The Power of Open Source
Billions of dollars in AI investments.
Thousands of research papers.
And now—condensed into just a few hundred lines of code. This is AI innovation at its finest—enabling researchers and developers worldwide to push AI forward faster than ever.
@debashis_dutta
-

Open Source Democratizes AI Innovation Across Researchers
By
–
-
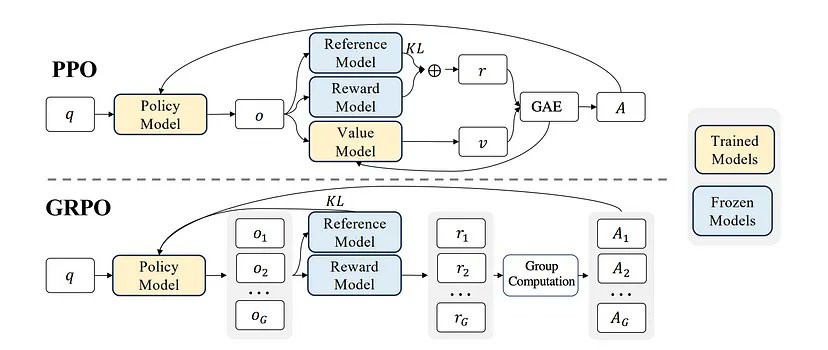
GRPO Democratizes AI Training Without Human Reward Labels
By
–
Why is this a game-changer? No human-labeled rewards → Fully autonomous learning Faster & more scalable RL → More efficient training Breakthrough in AI alignment → Smarter reward modeling
GRPO has the potential to democratize AI training—allowing for more -

GRPO: Grouped Reward Policy Optimization for RLHF Methods
By
–
What is GRPO (Grouped Reward Policy Optimization)? Most RLHF (Reinforcement Learning from Human Feedback) methods require: A separate reward model Labeled human preferences
GRPO removes these bottlenecks by dynamically estimating rewards directly from a group of -
DeepSeek R1 GRPO Open-Sourced: Revolutionary LLM Training
By
–
Day 8 – 25 Days of AI for ALL in 2025 DeepSeek R1’s GRPO is now fully open-source! A major breakthrough in LLM training—no separate reward models, no labeled data, just pure RL. More efficient, scalable & autonomous. Huge kudos to @deepseek_ai & thanks to
-
Your Role in Ethical AI Innovation and Development
By
–
7/ What’s Your Role in AI for ALL? Will you leverage this knowledge to innovate?
Will you champion ethical AI development? Read the full book here: https://
arxiv.org/abs/2501.09223 -
LLMs Drive Innovation in Healthcare, Finance, Education
By
–
6/ Why This Book Is a Game-Changer
LLMs are driving innovation in: Healthcare Finance Education
This book equips you to lead the AI revolution with tools, insights, and strategies for real-world impact. -
Ethical AI Alignment: RLHF and Responsible AI Development
By
–
5/ Chapter 4: Ethical Alignment Align AI with human values using Reinforcement Learning with Human Feedback (RLHF)
Learn advanced methods like reward modeling & preference optimization Build AI that’s not just powerful—but responsible! -
Master Chain-of-Thought Reasoning and Prompt Engineering
By
–
4/ Chapter 3: Prompting Mastery Unlock AI’s full potential with chain-of-thought reasoning
Master in-context learning for smarter, more intuitive AI
Leverage instruction-driven prompting to redefine workflows Revolutionize how AI works for you! -
Scaling LLMs: Long-Sequence Modeling and Distributed Training
By
–
3/ Chapter 2: Generative Models Learn how LLMs are scaled for massive datasets
Discover long-sequence modeling & distributed training
Decode the scaling laws behind state-of-the-art models Build systems that go BIG! -
Pre-training Foundations: Self-supervised Learning and LLM Architectures
By
–
2/ Chapter 1: Pre-training Foundations
Demystify self-supervised learning
Explore architectures like encoder-decoder models
See how pre-training powers scalability in AI Master the backbone of LLMs like BERT!