
> Hunyuan-Large just released by @TencentGlobal : Largest ever open MoE LLM, only 52B active parameters but beats LLaMA 3.1-405B on most academic benchmarks! Key insights: Mixture of Experts (MoE) architecture: 389 B parameters in total, but only 52B are activated for any
@aymericroucher
-
CLEAR: First Benchmark for Machine Unlearning
By
–
> CLEAR: first benchmark to make models forget what we want them to forget! With privacy concerns rising, we sometimes need our models to "forget" specific information – like a person's data – while keeping everything else intact. Researchers just released CLEAR, the first
-
Oasis: First AI-Generated Real-Time Video Game Without Engine
By
–
> Oasis: First Real-Time Video Game Without a Game Engine! 🎮@DecartAI & @Etched just released Oasis – a fully AI-generated video game running at 20 FPS (frames per second). The model takes keyboard inputs and generates everything – physics, rules, graphics – on the fly,… pic.twitter.com/DU6l3PBfhF
— m_ric (@AymericRoucher) 1 novembre 2024> Oasis: First Real-Time Game Without a Game Engine! @DecartAI & @Etched just released Oasis – a fully AI-generated video game running at 20 FPS (frames per second). The model takes keyboard inputs and generates everything – physics, rules, graphics – on the fly,
-
Tool use mastered by a Minecraft-generating LLM
By
–
If I had known that "Tool use" would be first mastered by a Minecraft-generating LLM… (cf the video at 0:32)
-

Highlights from OpenAI DevDay: image model, o1 coding paradigm, Realtime API
By
–
> Highlights from yesterday’s @OpenAI DevDay in London: image model in the works, o1’s new coding paradigm, Realtime API o1 creates a new paradigm for code. OpenAI devs seem to have massively adopted o1 + Cursor, seems like the experience is vastly improved compared to GH
-
Build for future LLM strengths, don’t plug holes
By
–
SamA expects most shortcomings of LLMs to progressively disappear across future generations
=> Do not build a tool that plugs a hole, that goes around one shortcoming of the model, but instead build a model that leverages future strengths How can one justify trillions of -

OpenAI Dev Day Q&A: o1 models, larger models, startup integration
By
–
Ongoing Q&A with @sama at @OpenAI 's dev day! Should we expect o1 like models or more larger models?=> Wants to make LLMs better across the board but this direction of reasoning is important How far wil the go up the integration? What should AI startup builders on top of OpenAI
-

Tricking Sam Altman into releasing GPT-3.5 at DevDay
By
–

Trying to trick @sama into releasing GPT-3.5 at OpenAI's DevDay in London!
-
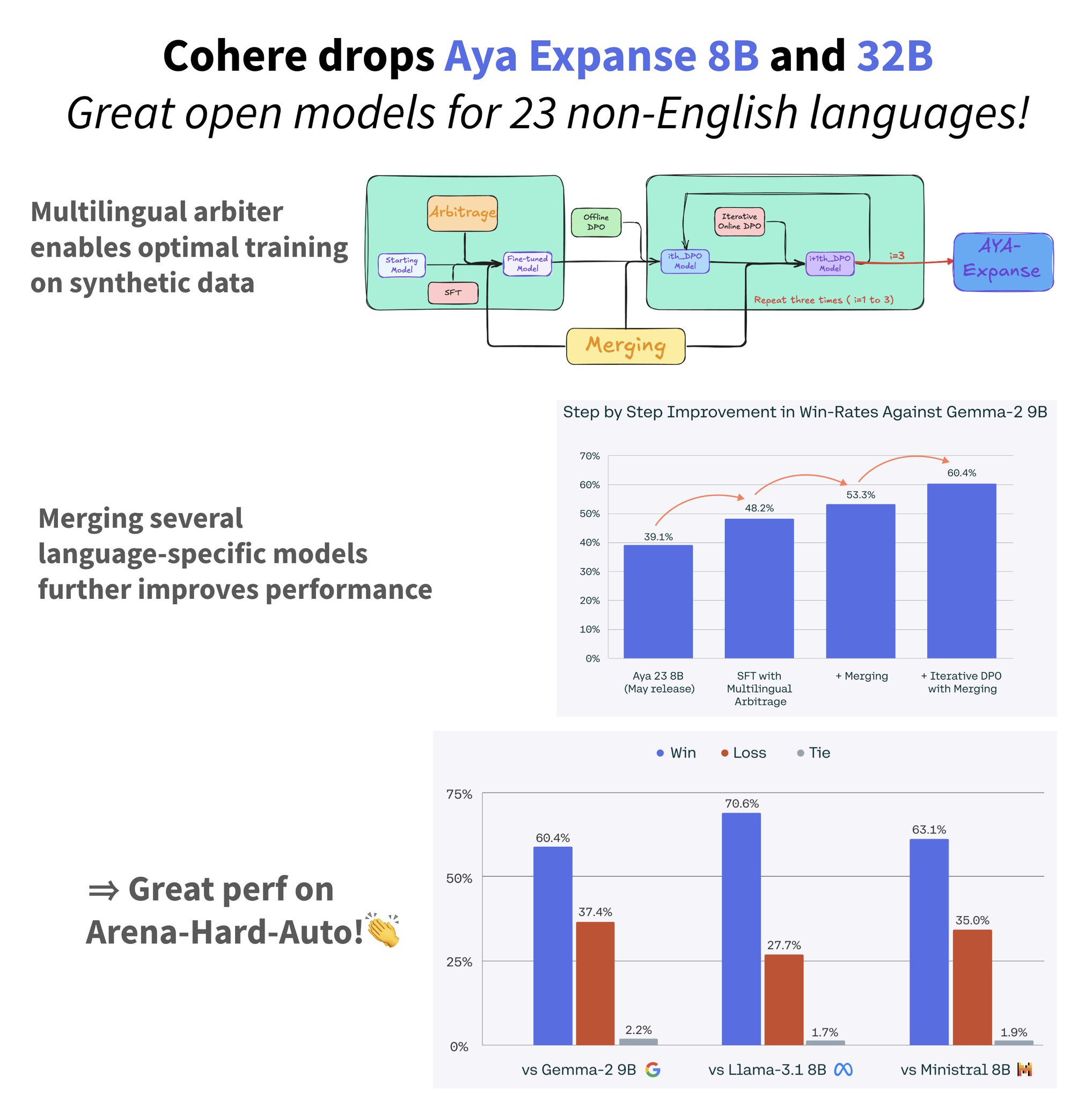
Cohere releases Aya 8B & 32B multilingual models for 23 languages
By
–
Cohere releases Aya 8B & 32B: SOTA multilingual models for 23 languages ! @cohere just dropped two great models: great on generalist use, they specifically shine on 23 non-english languages. How did they pull that multilingual trick? 𝗧𝗿𝗮𝗶𝗻 𝗼𝗻 𝘀𝘆𝗻𝘁𝗵𝗲𝘁𝗶𝗰
-

New Claude 3.5 models outperform GPT-4o
By
–
New agentic powerhouse: upgraded Claude 3.5 Sonnet leaves GPT-4o in the dust Anthropic just announced two extremely impressive releases, with an improved Claude 3.5 Sonnet and a new Claude 3.5 Haiku ! (Haiku previously only existed in version 3) Claude 3.5 Sonnet: a