We also compare LLMs with human baselines. Although human responses are not perfect, they outperform GPT-4 (0314) by a substantial margin. Furthermore, like GPT-4 (0314), non-expert humans struggle with non-square grid shapes.
6/n
@_yutaroyamada
-

Human Baselines Outperform GPT-4 on Non-Square Grid Tasks
By
–
-
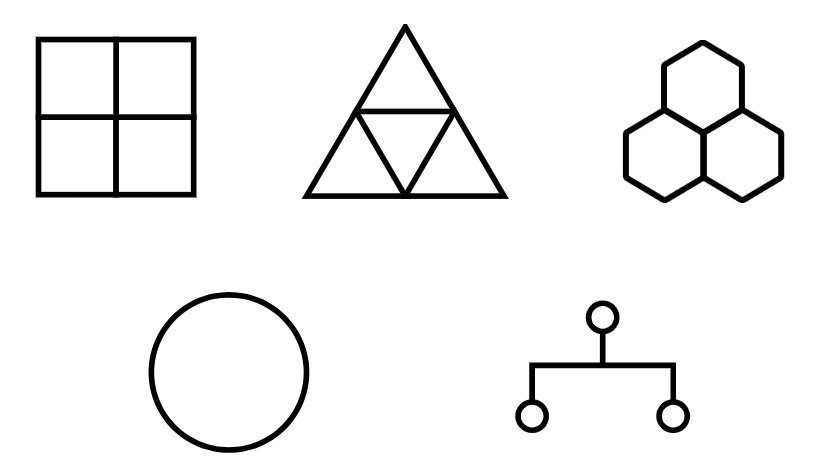
LLM Performance Variability Across Different Spatial Structures
By
–
We examine various spatial structures (squares, triangles, hexagons, rings, and trees), which reveal substantial variability in LLM performance across different structures. (GPT-4 here is 0314)
5/n -
Loop Closure in Square Grid: Claude 3 vs GPT-4 Comparison
By
–
Answering this question correctly demonstrates an understanding of loop closure in the square grid, which is a fundamental aspect of this spatial structure. The Claude 3 vs. GPT-4 comparison above is tested on a 3 by 3 square grid w/ 8 navigational steps. 4/n
-

Sequential Transitions Enable LLM Spatial Understanding
By
–
Motivated by this, we hypothesize that presenting sequential transitions might be enough for LLMs to achieve spatial understanding. e.g. if a model comprehends a square map’s structure, it should be able to answer the question shown in the image. 3/n
-
Evaluating Spatial Understanding in Text-Only Language Models
By
–
Evaluating the text-only models’ understanding of spatial information is tricky because text-only LLMs do not explicitly interact with the physical world. But humans can implicitly learn representations that mirror spatial structures only from sequential navigational data. 2/n
-

Claude 3 vs GPT-4: Spatial Reasoning Task Comparison
By
–
A quick comparison b/w Claude 3 and GPT-4 on a spatial reasoning task (n=100, 5 run average w/ temp=1.0). Seems like Claude 3 still beats GPT-4, and gpt-4-turbo performs worse than gpt-4-0613. Interesting contrast to their perf in chat & coding, where GPT-4 comes out ahead. 1/n
-
CLIP Binding Problem and CAB Instance Discussion
By
–
Thank you for the reference! The original motivation was indeed to investigate the binding problem of CLIP, and in the paper we discuss that CAB is an instance of the binding problem.
-
Prompt Variation Effects on Similarity Scores in Image Retrieval
By
–
Haven't done image retrieval experiments. We did vary prompts and observed things like the similarity score for "lemon is eggplant" is higher than "lemon is purple" etc.
-
arxiv paper link shared with camera-ready version update
By
–
Link to the paper: https://
arxiv.org/abs/2212.12043 (will update this with the camera-ready version shortly.) -
Zero-shot Classification with Color Labels and Part-whole Attributes
By
–
Yes, we did zero-shot classification / candidate matching and labels we used for the fruit-vegetable dataset are “red”,
“yellow”, “purple”, “green”, and “orange”. We also observed CAB for part-whole attributes, although it was not as severe as the color attributes.