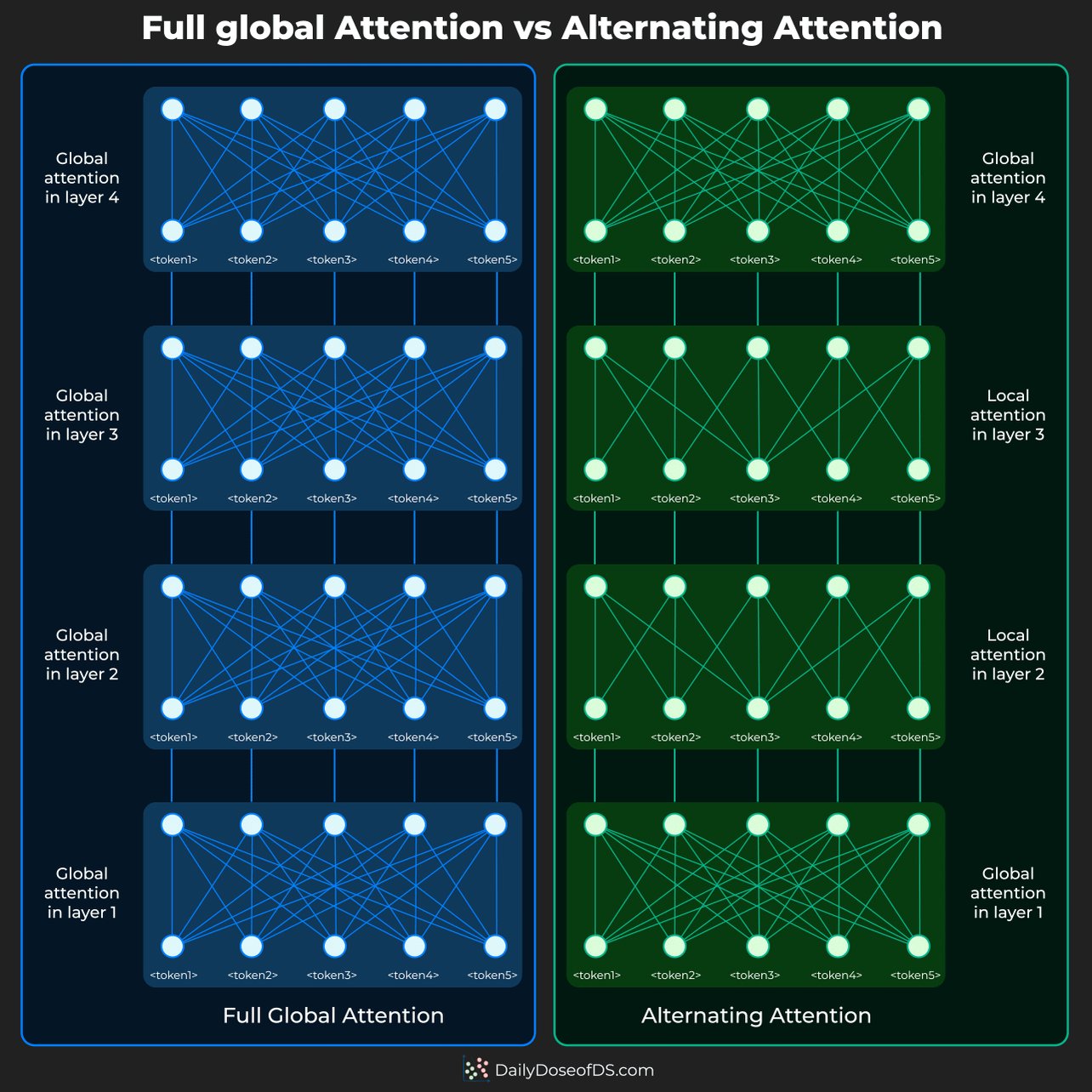
Lightning Attention architecture used in MiniMax M2.5 is really interesting. The structure is 7 Lightning Attention layers for every 1 traditional SoftMax attention layer, which lets it scale to long contexts while keeping the quality you'd expect from standard transformers. I… pic.twitter.com/HnfTF0W6f1
— Akshay 🚀 (@akshay_pachaar) 14 mars 2026
Lightning Attention architecture used in MiniMax M2.5 is really interesting. The structure is 7 Lightning Attention layers for every 1 traditional SoftMax attention layer, which lets it scale to long contexts while keeping the quality you'd expect from standard transformers. I