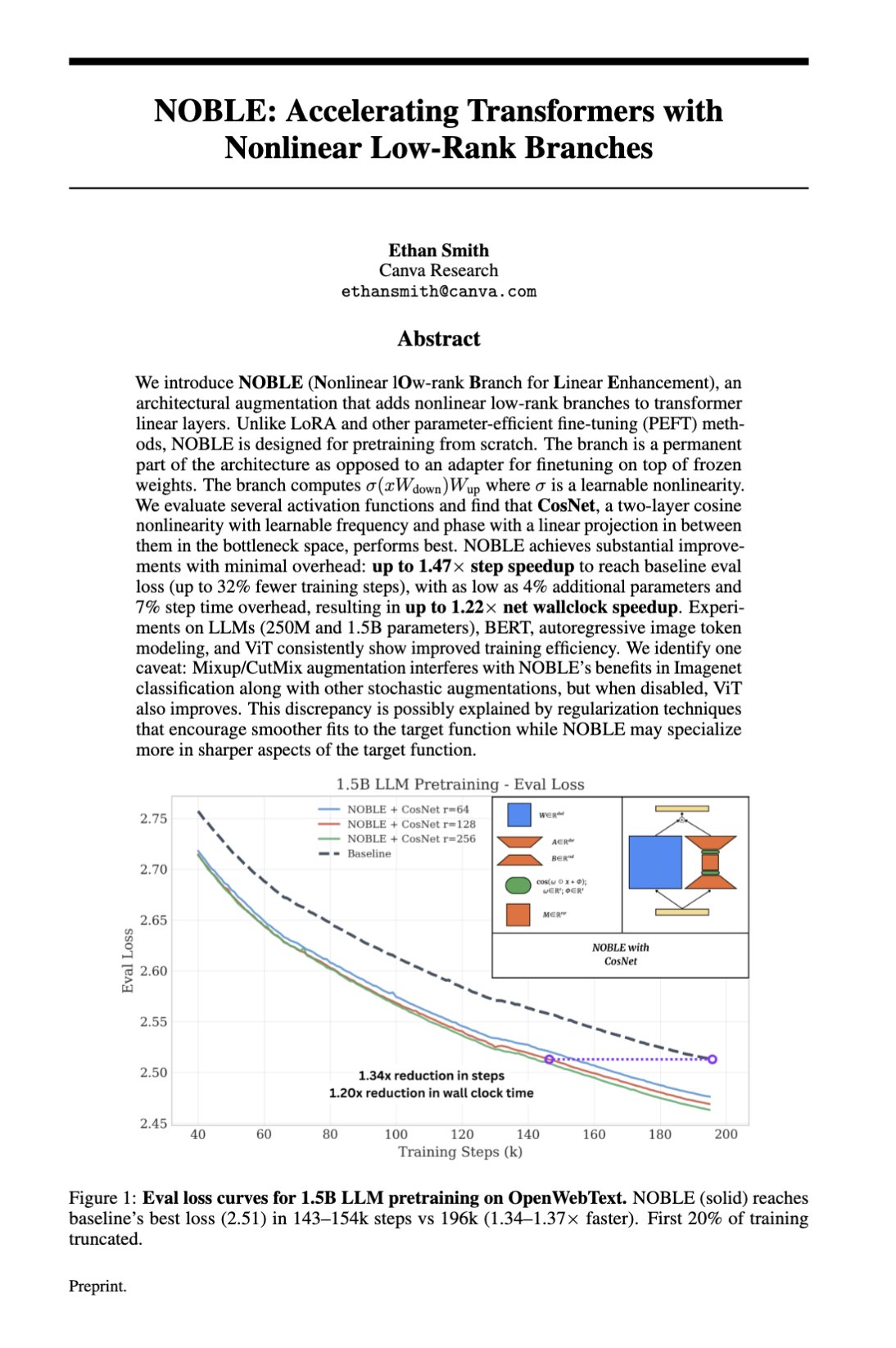
"NOBLE: Accelerating Transformers with Nonlinear Low-Rank Branches" This paper shows that if you add a tiny permanent nonlinear low rank branch (with a cosine bottleneck) to each Transformer linear layer, you can teach the model hard-to-fit details much more efficiently. This
NOBLE: Nonlinear Low-Rank Branches Accelerate Transformers
By
–