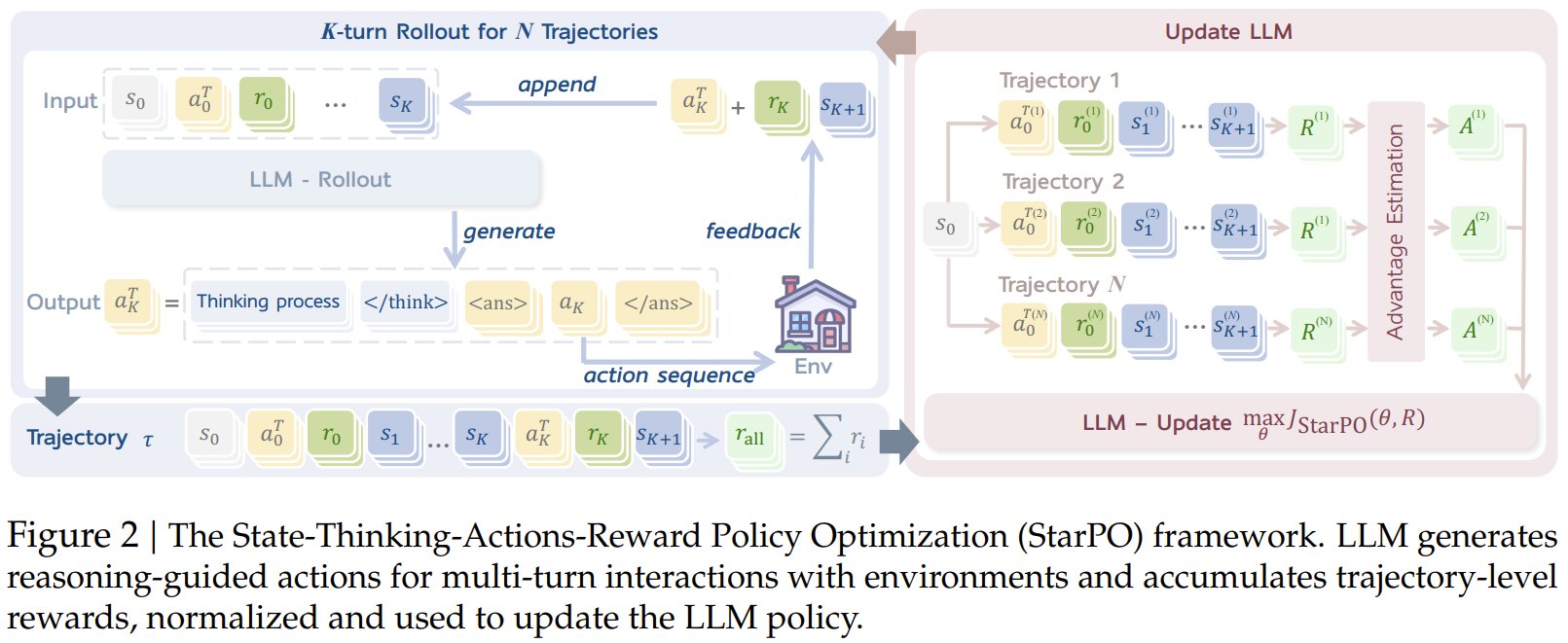
Training LLM agents with RL sounds promising—until they fall into the Echo Trap.
New research shows how multi-turn training destabilizes fast, and how StarPO fixes it with better reward shaping and trajectory control.
Without it? Agents just hallucinate reasoning.
They also
StarPO Fixes Echo Trap in Multi-Turn LLM Agent Training
By
–