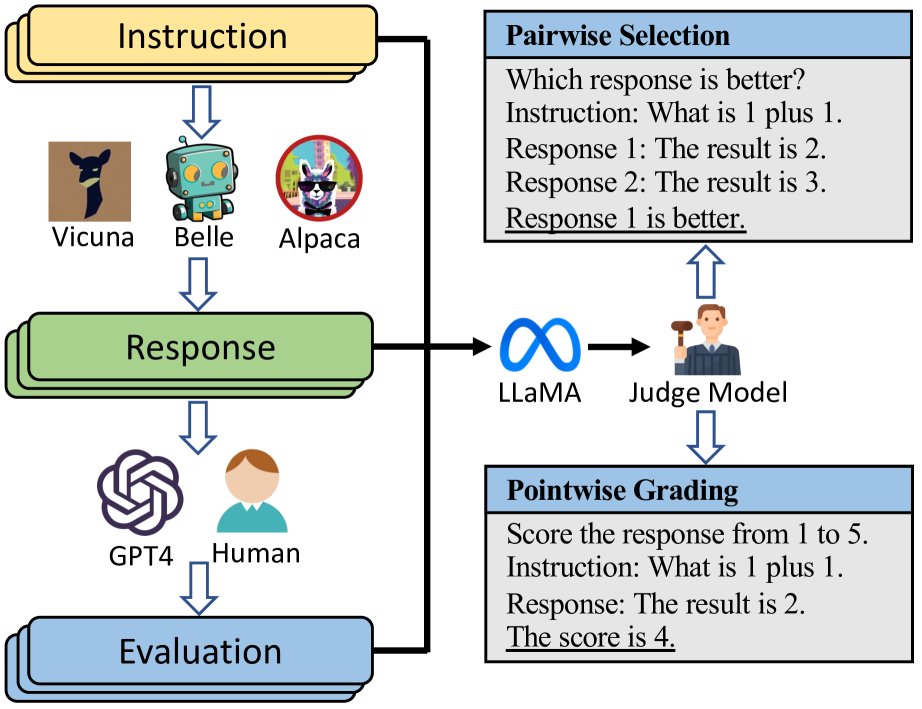
I reviewed the dark field of LLM-as-a-judge so you don't have to. Here are the key findings. Model Performance Variability
LLMs show inconsistent performance across datasets and tasks. No single model dominates all scenarios. GPT-4 generally leads, with open-source models like
LLM-as-a-Judge Performance: Key Findings and Model Variability
By
–