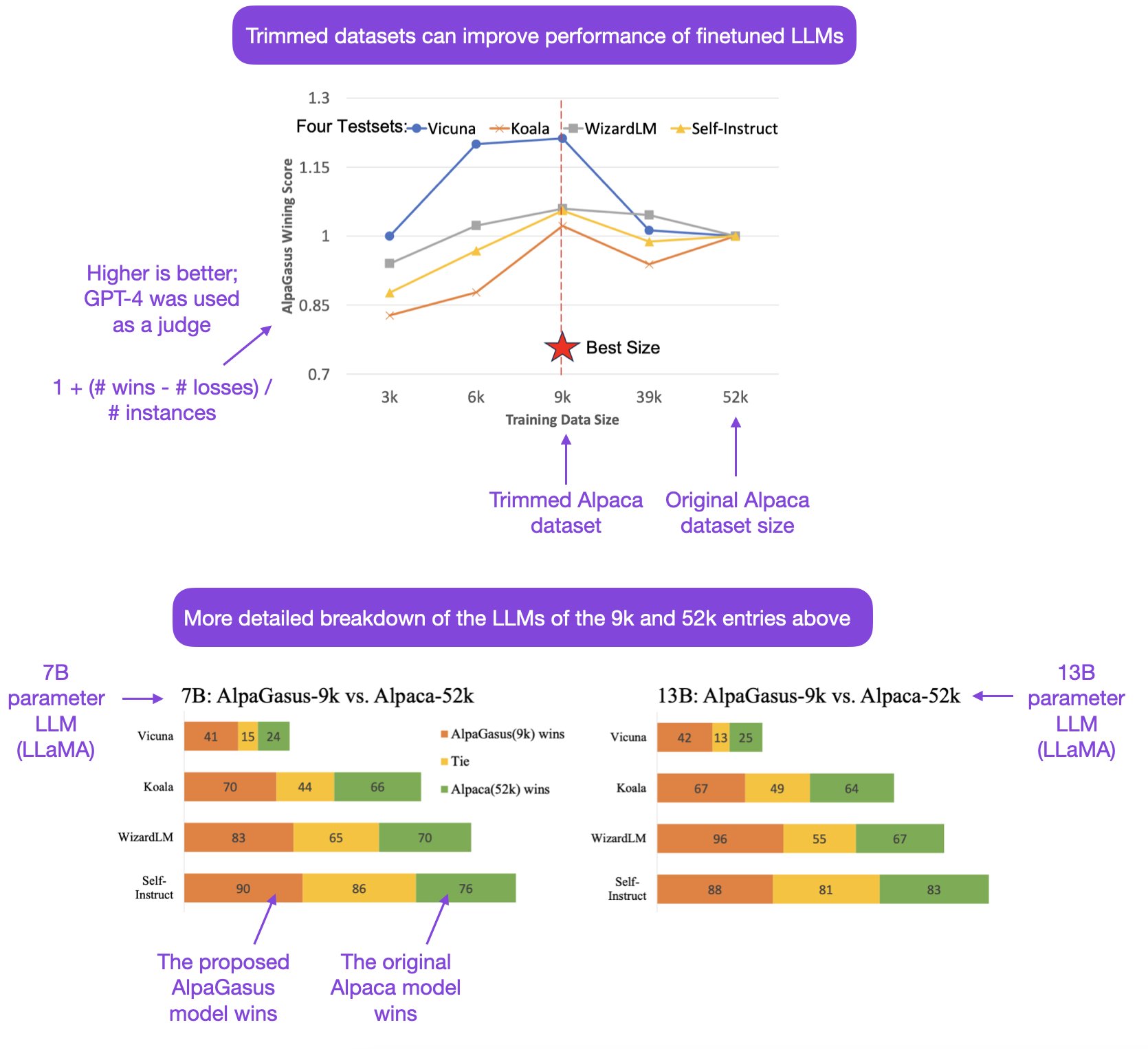
Next to LIMA, this is another interesting paper highlighting that more data is not always better when finetuning LLMs: https://
arxiv.org/abs/2307.08701 Trimming the orig 52k Alpaca dataset to 9k can improve the performance when finetuning 7B and 13B parameter LLMs.
Less Data Better Results Finetuning LLMs with Trimmed Datasets
By
–