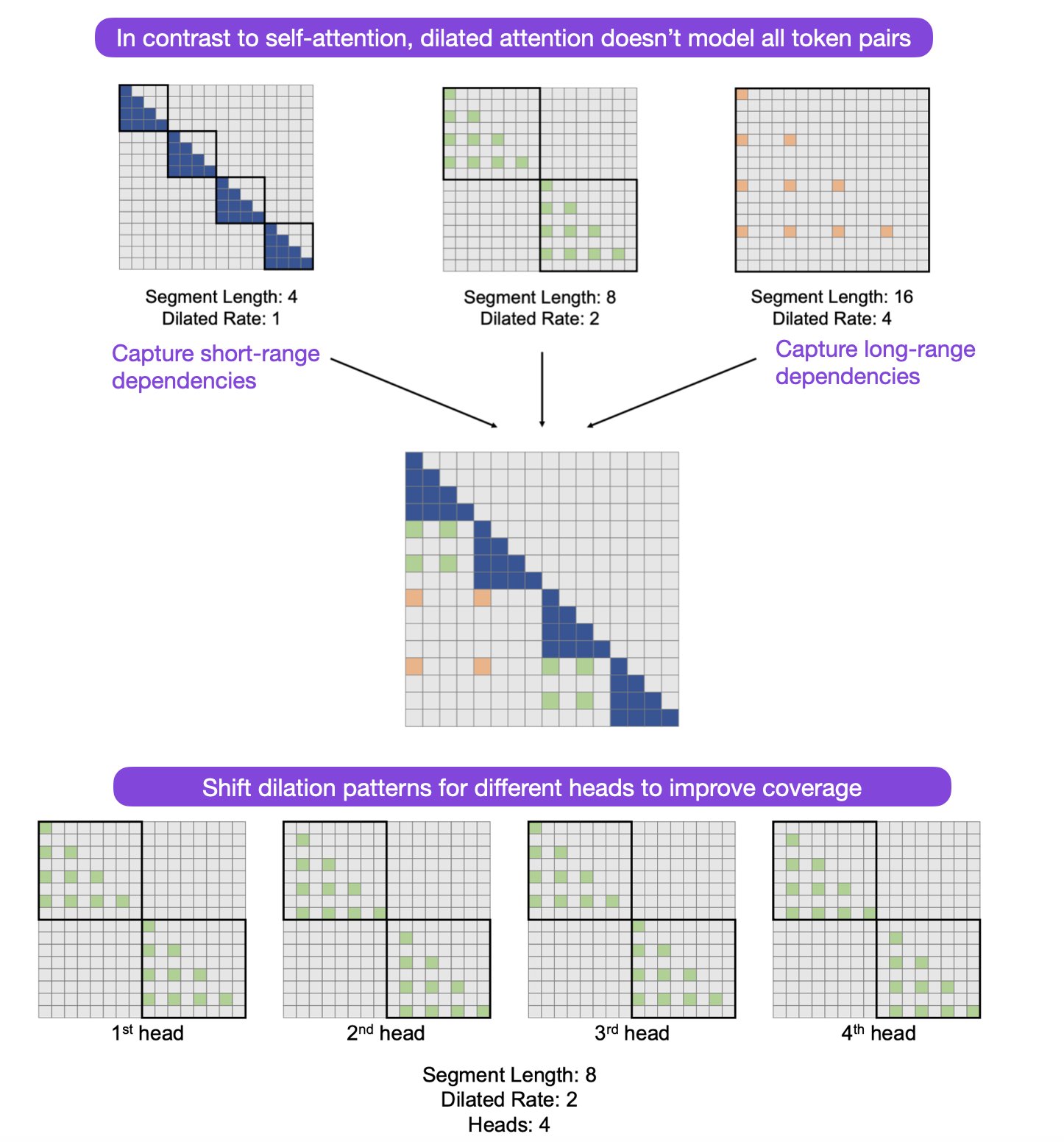
We had 1) the RMT paper on scaling Transformers to 1M tokens, and 2) the convolutional Hyena LLM for 1M tokens. How about 3) LONGNET: Scaling Transformers to 1 Billion Tokens (
https://
arxiv.org/abs/2307.02486)!? It achieves linear (vs quadratic) scaling via dilated (vs self) attention.
LongNet: Scaling Transformers to 1 Billion Tokens with Dilated Attention
By
–