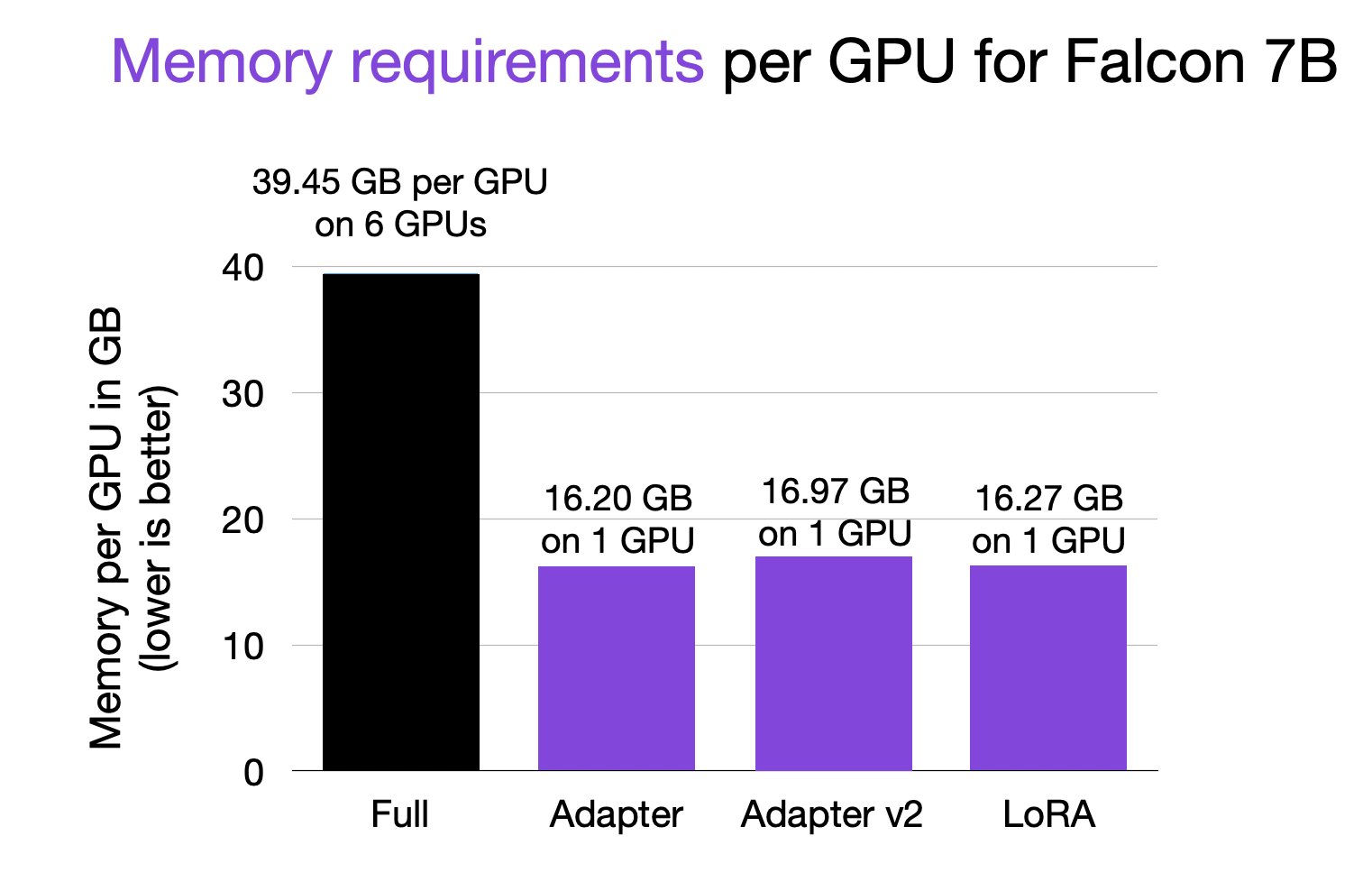
Btw, it's also a big reduction in memory: 16 gigs instead of 6 x 40 GB. Due to the reduced parameter counts in the backward pass: Full finetuning: 7,217,189,760
Adapter: 1,365,330
Adapter v2: 3,839,186
LoRA: 3,506,176 (I used LoRA rank of 16 to match Adapter v2 above.)
Memory reduction: Full finetuning vs Adapter vs LoRA comparison
By
–