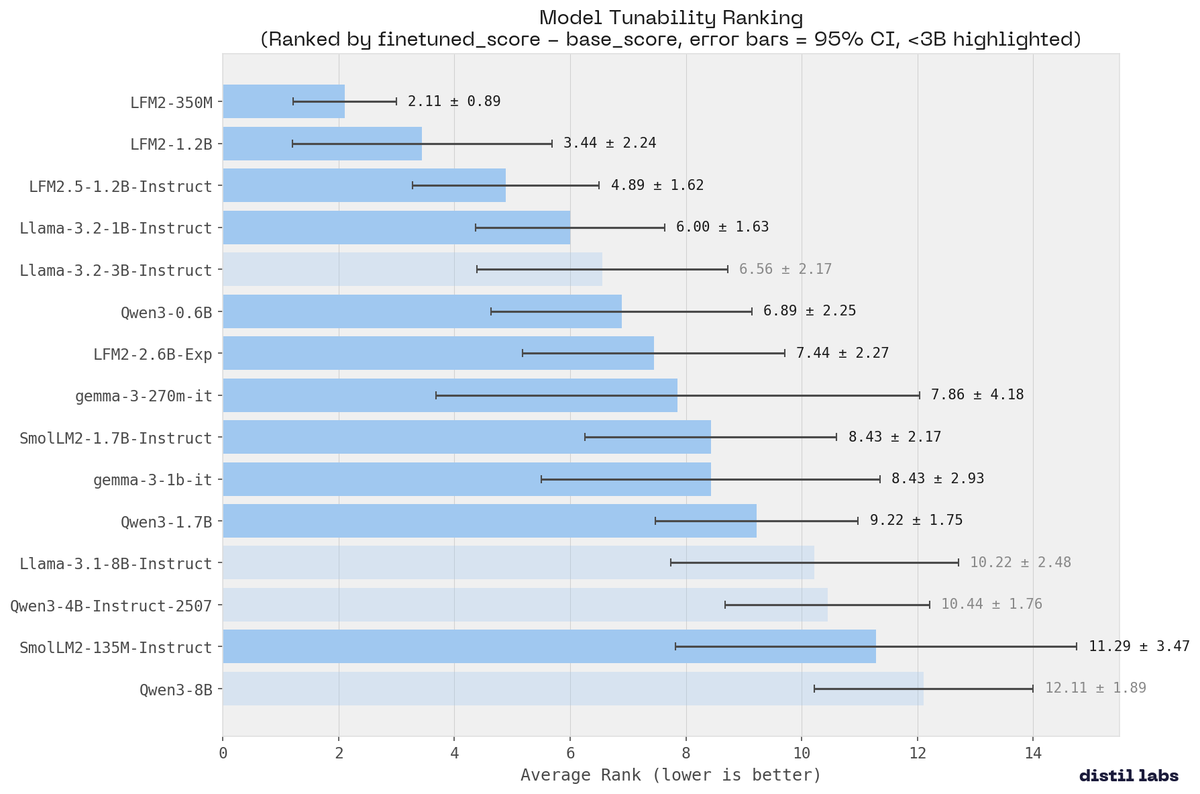
Very interesting results about the fine-tunability of different models. 👀 LFM2 is more flexible than alternatives. It also confirms some common knowledge about RL degrading fine-tuneability. Jacek Golebiowski (@j_golebiowski) We benchmarked 15 small language models across 9 tasks to find out which one you should actually fine-tune. The most surprising result: Liquid AI's LFM2-350M ranked #1 for tunability. 350M parameters, absorbing training signal more effectively than models 20x its size. The entire LFM2 family swept the top 3 spots. No other architecture came close. LFM2-350M: avg rank 2.11 (±0.89) LFM2-1.2B: avg rank 3.44 LFM2.5-1.2B-Instruct: avg rank 4.89 That tight CI means it's consistent across every task type, not just a few lucky benchmarks. — https://nitter.net/j_golebiowski/status/2033611679645266280#m
→ View original post on X — @maximelabonne, 2026-03-16 19:06 UTC