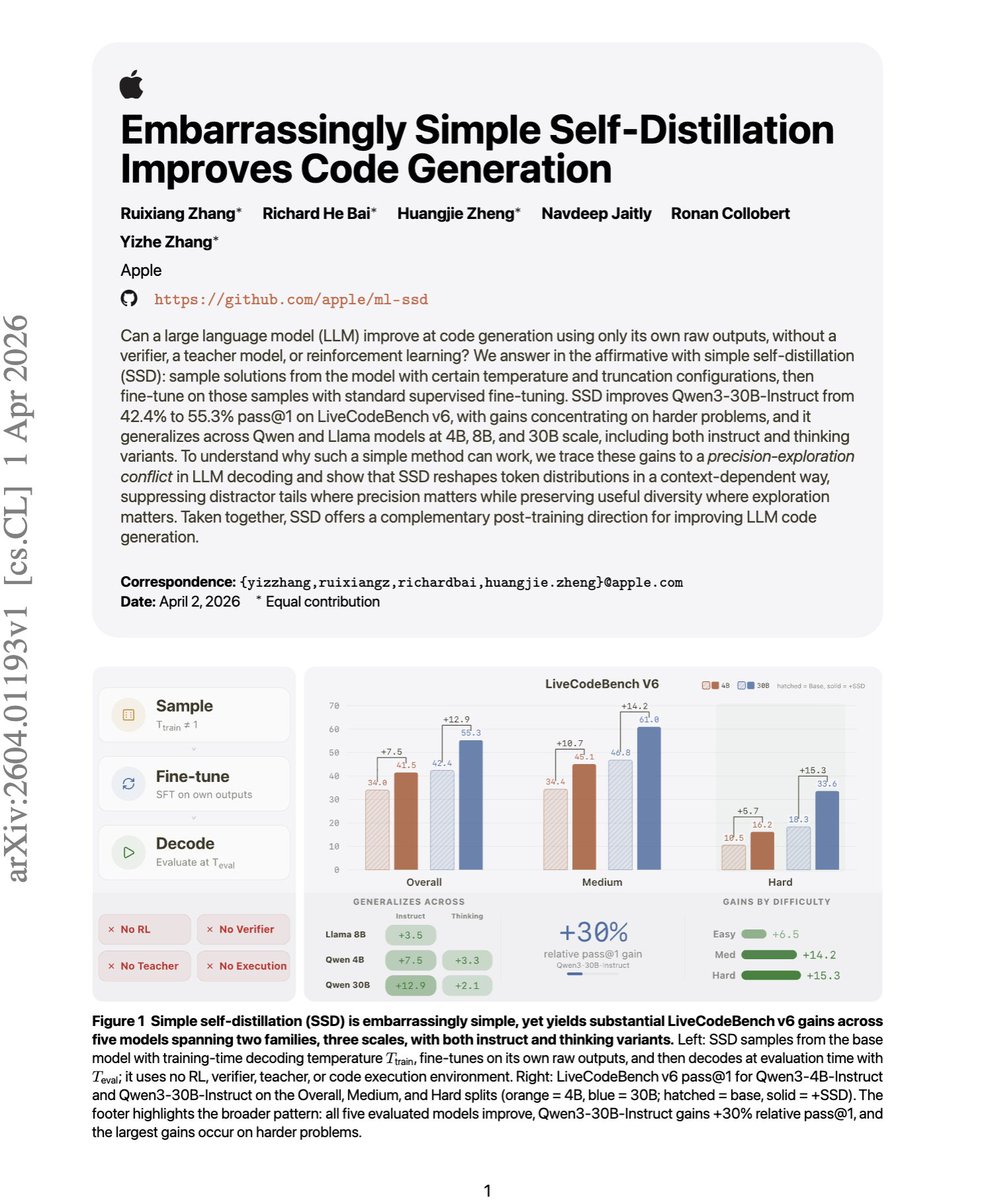
Most code-improvement methods need extra heuristic work, either a stronger teacher, an execution-based filtering, or RL. But this paper shows that the model can get much better at code generation by training on its own raw outputs, even though those outputs are not verified, not filtered for correctness, and not produced by a stronger teacher. What makes it even more surprising is that the gains are largest on harder problems, and simple decoding tricks alone cannot recover them. The most counterintuitive result is that it can still help even when the self-generated training data is partly garbage. The paper shows a high-temperature setting where many outputs become gibberish, yet the fine-tuned model still improves materially. That suggests the benefit is not mainly coming from learning correct programs, but from reshaping the model's token probabilities in a better way. Empirically, Qwen3-30B-Instruct improves from 42.4% to 55.3% pass@1 on LiveCodeBench v6, with the biggest gains on harder problems. [Translated from EN to English]
→ View original post on X — @askalphaxiv, 2026-04-05 18:25 UTC