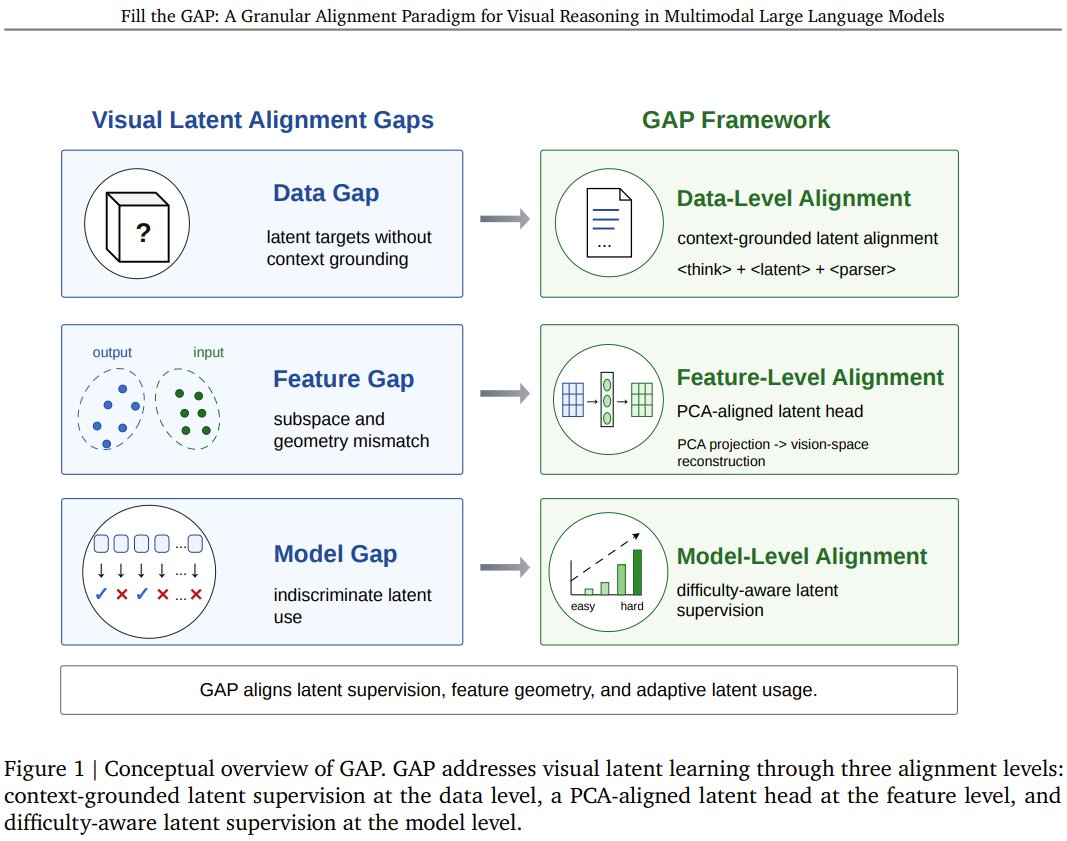
Why do multimodal AI models struggle to “think” visually without external tools? Alibaba, University of Waterloo, and the Vector Institute present GAP—a new method that fixes a hidden mismatch in how models generate internal visual evidence. Instead of feeding raw decoder
GAP fixes hidden mismatch in multimodal AI visual evidence generation
By
–