Do your language models truly grasp meaning, or are they just pretending? Researchers from Beijing University of Science and Technology and BIGAI present SemanticQA — a new benchmark that evaluates LMs' ability to handle expressions.
By
–
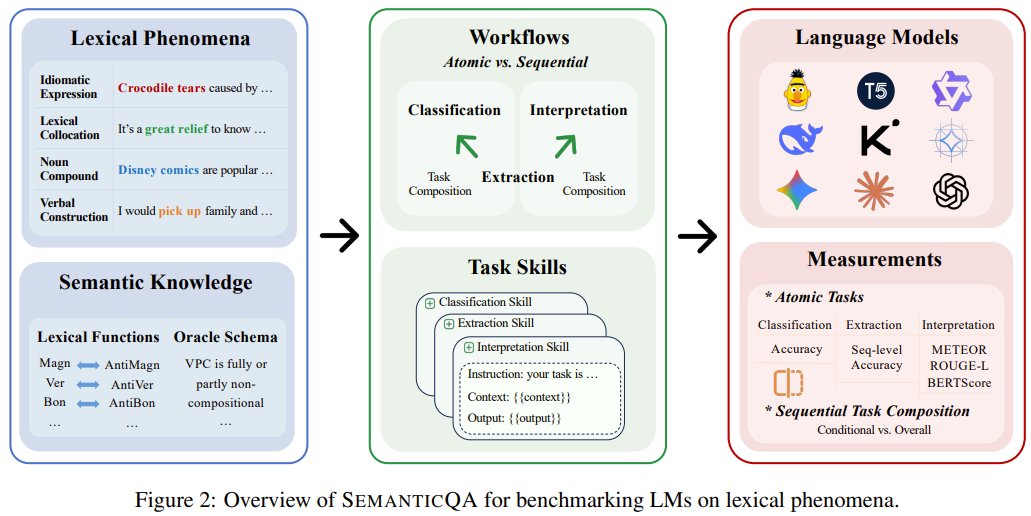
Do your language models truly grasp meaning, or are they just pretending? Researchers from Beijing University of Science and Technology and BIGAI present SemanticQA — a new benchmark that evaluates LMs' ability to handle expressions.