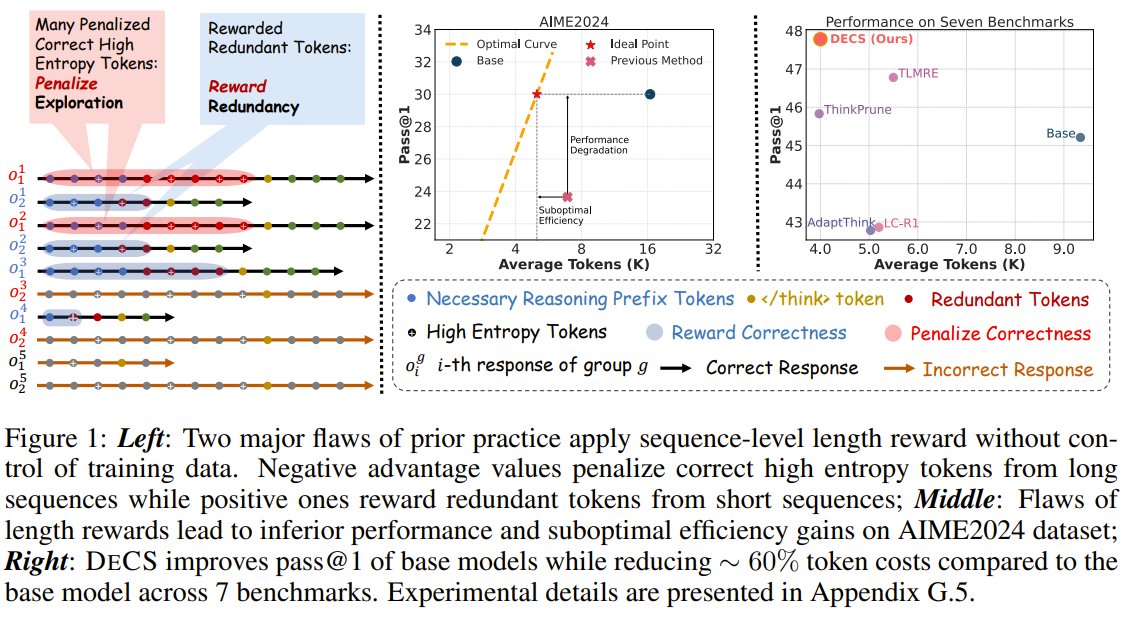
Overthinking is killing LLM reasoning efficiency. DECS fixes it by surgically cutting redundant tokens without hurting performance. Current RLVR models generate excessively long reasoning paths with zero gain. Existing length penalties backfire—they penalize essential
DECS fixes LLM overthinking by cutting redundant tokens
By
–