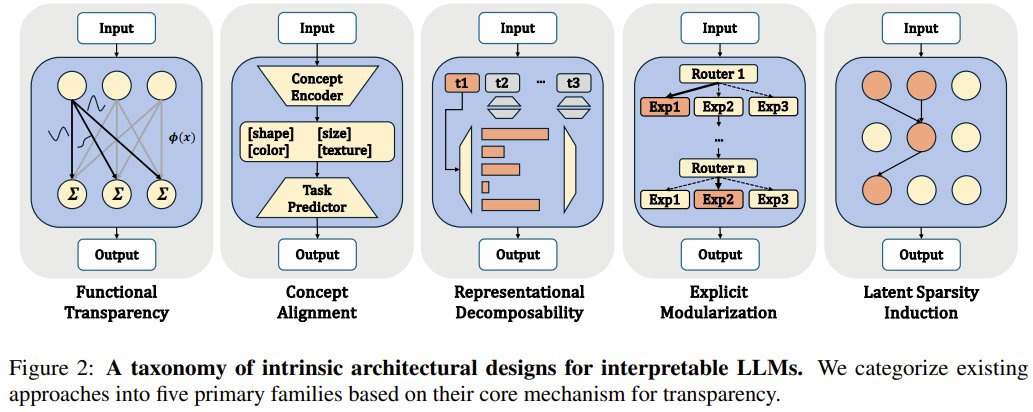
Can we finally trust what LLMs are really thinking? Yutong Gao and researchers from Peking University, Purdue, and Nanjing University present a new survey on intrinsic interpretability — building transparency directly into model architecture rather than relying on post-hoc
New Survey on Intrinsic Interpretability in LLM Architectures
By
–