David Silver RL Lecture 4: Model-Free Prediction
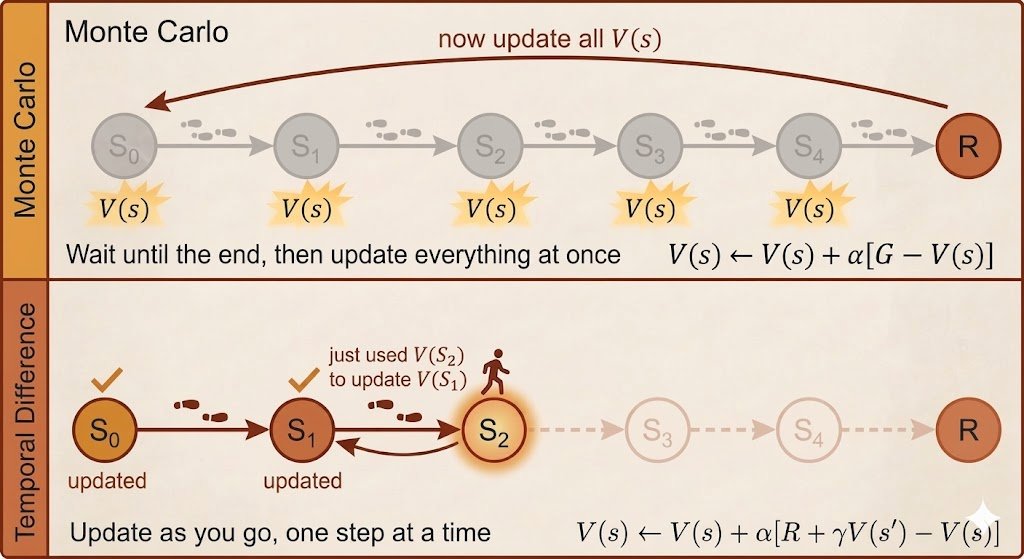
A core RL question: how do we evaluate a policy without knowing the environment model? Monte Carlo: learn from full returns after complete episodes.
Temporal Difference: learn earlier from reward + bootstrapped next-state value. My note:
https://ickma2311.github.io/ML/RL/david-silver-lecture-4-model-free-prediction.html [Translated from EN to English]
→ View original post on X — @ceobillionaire, 2026-04-12 01:18 UTC