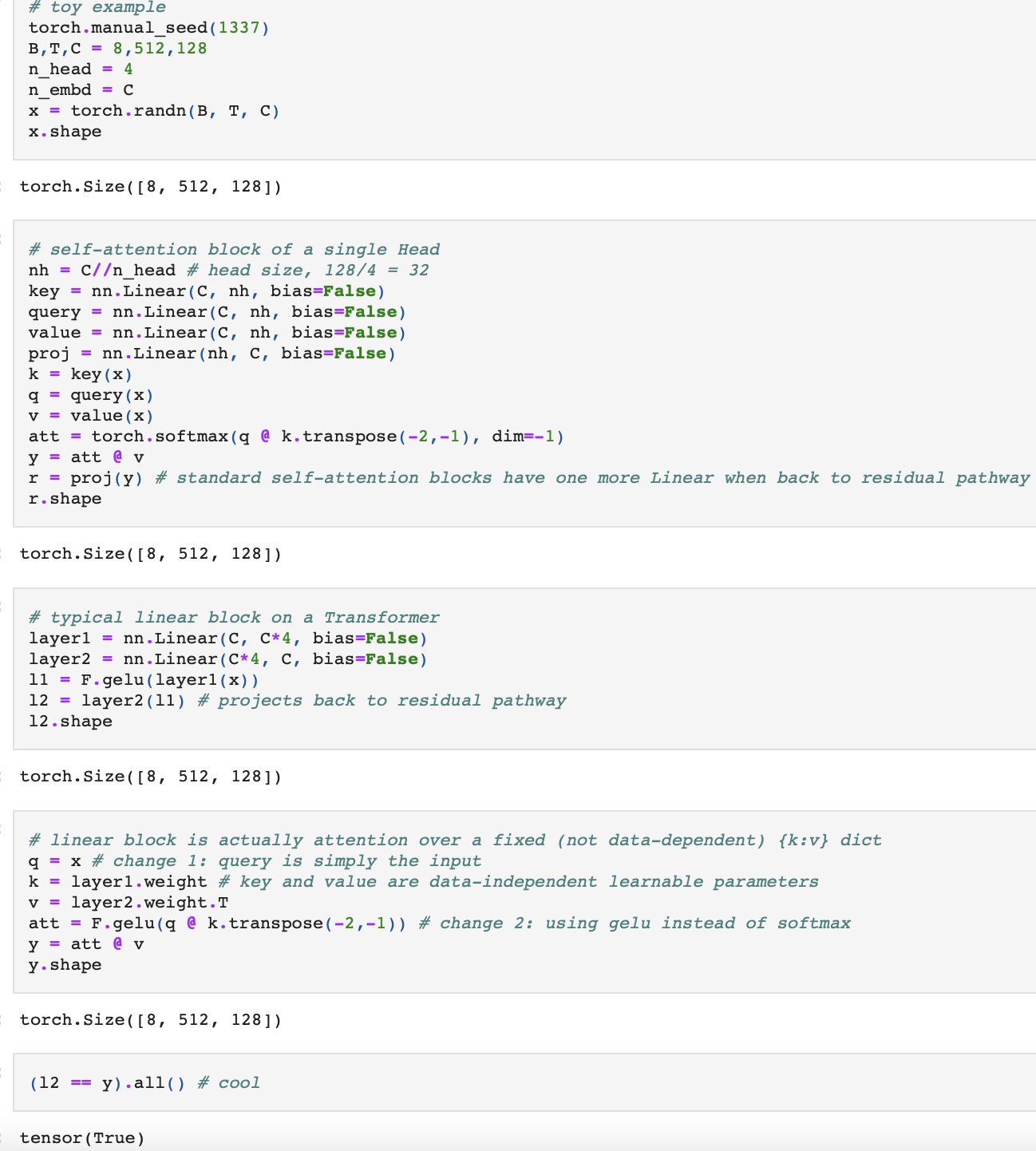
Random quick note on Transformer block unification. People are usually a bit surprised that the MLP and Attention blocks that repeat in a Transformer can be re-formated to look very similar, likely unifiable. The MLP block just attends over data-independent {key: value} nodes: