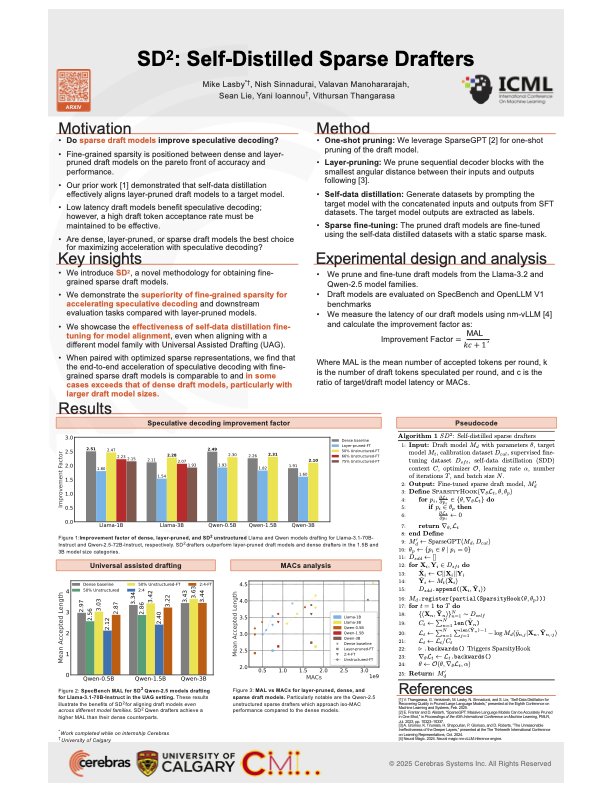
Featured Paper at @icmlconf – The Internationall Conference on Machine Learning: SD² – Self-Distilled Sparse Drafters Speculative decoding is a powerful technique for reducing the latency of Large Language Models (LLMs), offering a fault-tolerant framework that enables the
SD² Self-Distilled Sparse Drafters Speeds Up LLM Inference
By
–