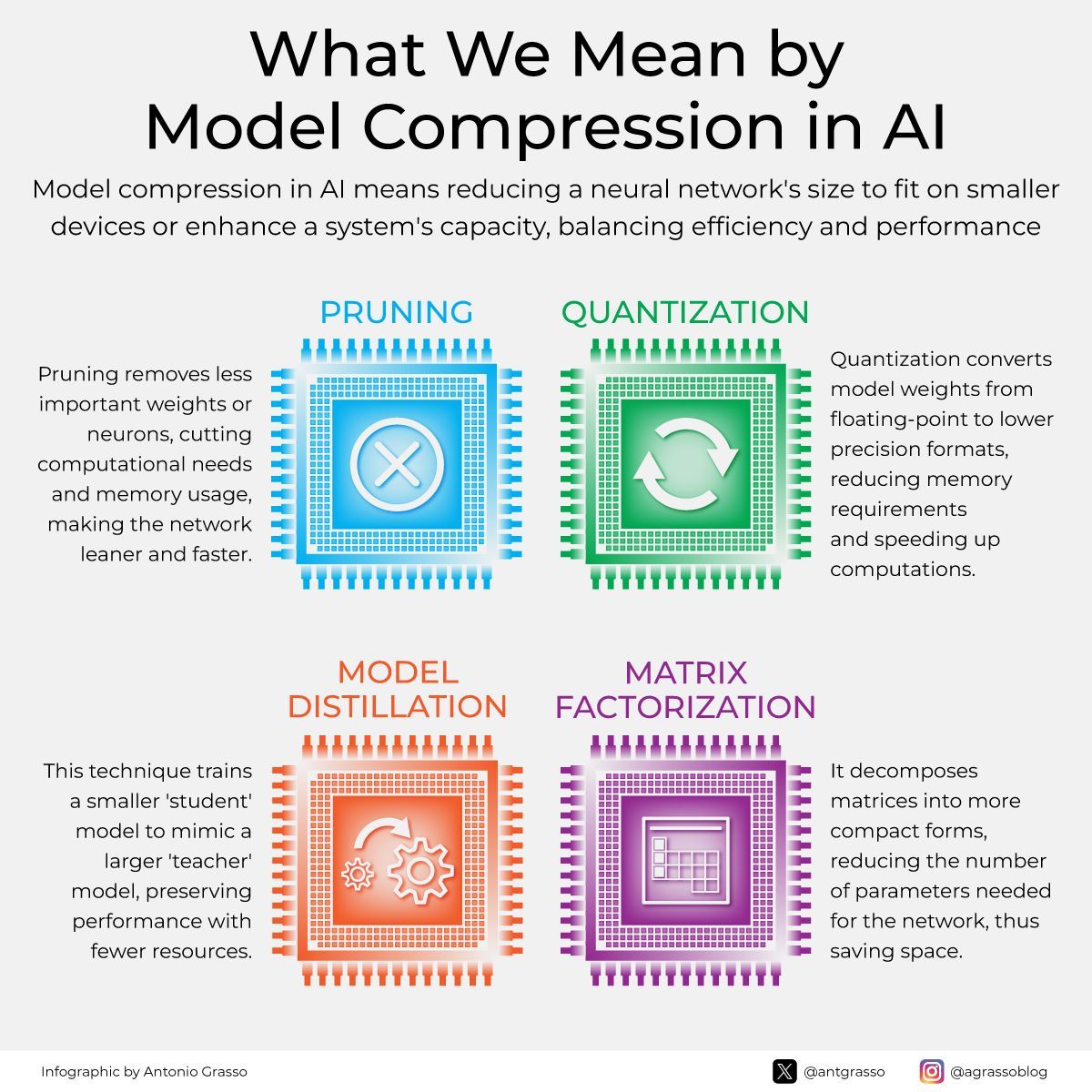
Model compression in AI utilizes pruning, quantization, model distillation, and matrix factorization to shrink network size and enhance computational speed while preserving performance, enabling robust functionality on devices with limited resources. Microblog @antgrasso #ai
Model Compression Techniques Enhance AI Performance on Edge Devices
By
–