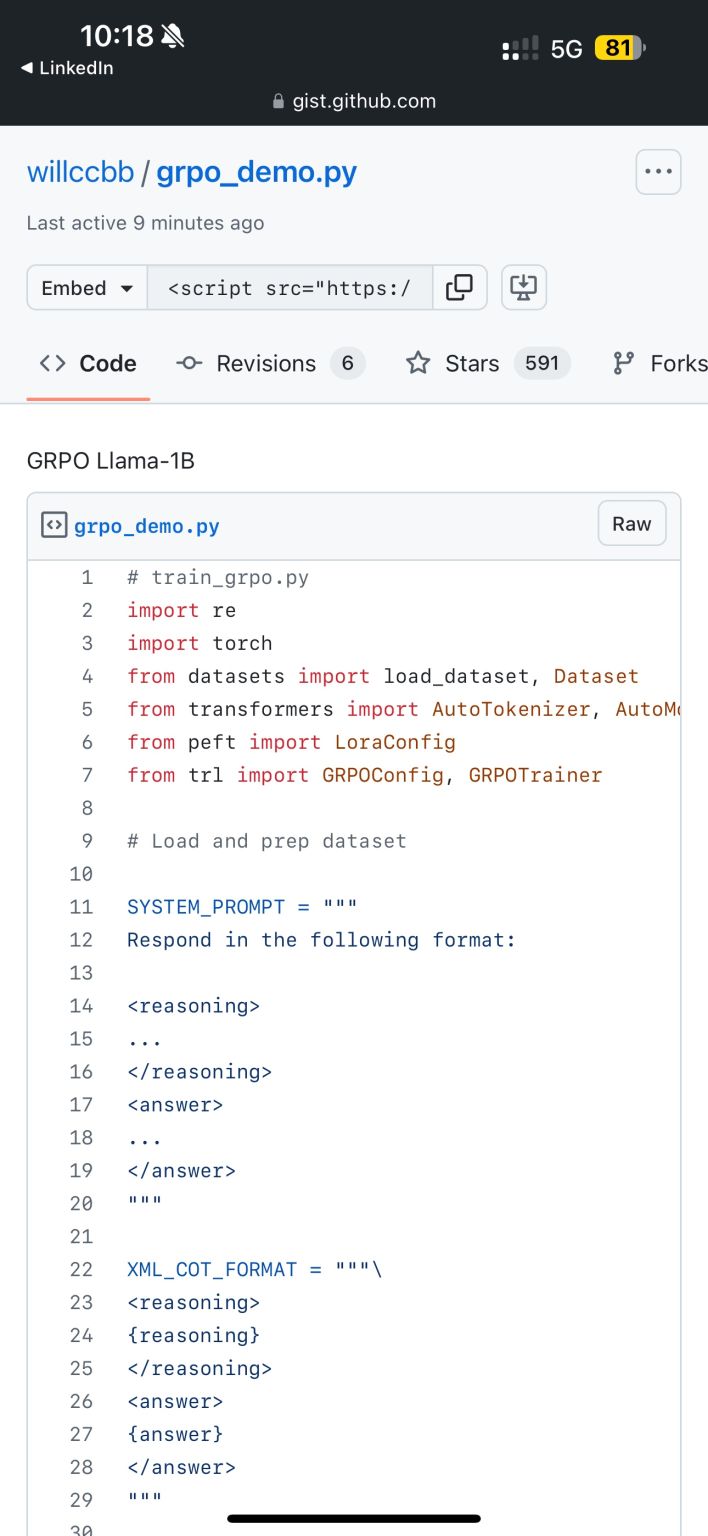
Day 8 – 25 Days of AI for ALL in 2025 DeepSeek R1’s GRPO is now fully open-source! A major breakthrough in LLM training—no separate reward models, no labeled data, just pure RL. More efficient, scalable & autonomous. Huge kudos to @deepseek_ai & thanks to
DeepSeek R1 GRPO Open-Sourced: Revolutionary LLM Training
By
–