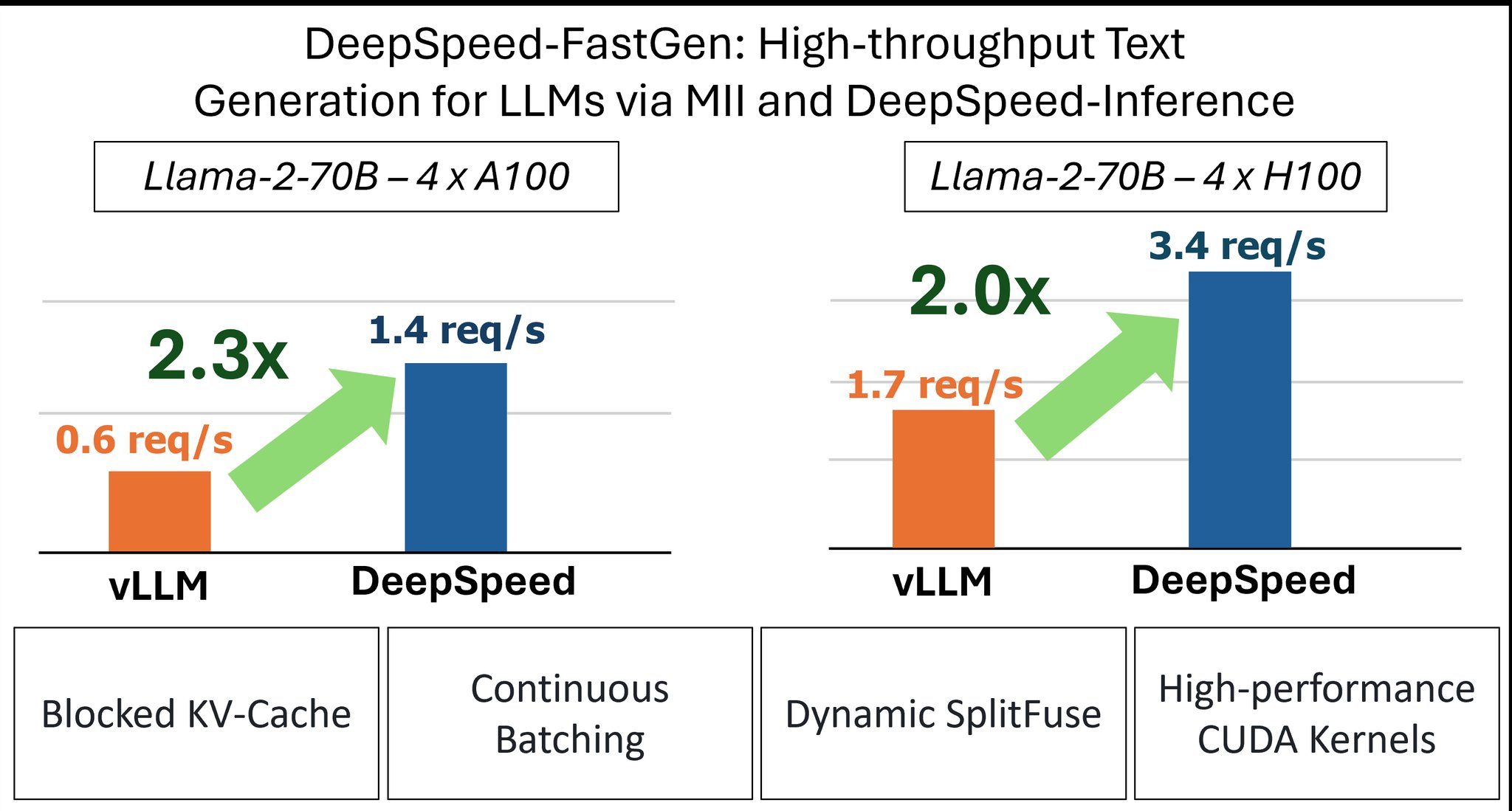
Introducing DeepSpeed-FastGen V/ @MSFTDeepSpeed **************
Serve LLMs and generative AI models with
– 2.3x higher throughput
– 2x lower average latency – 4x lower tail latency
w. Dynamic SplitFuse batching Auto TP, load balancing w. perfect linear scaling, plus
DeepSpeed-FastGen: 2.3x Throughput Improvement for LLM Serving
By
–