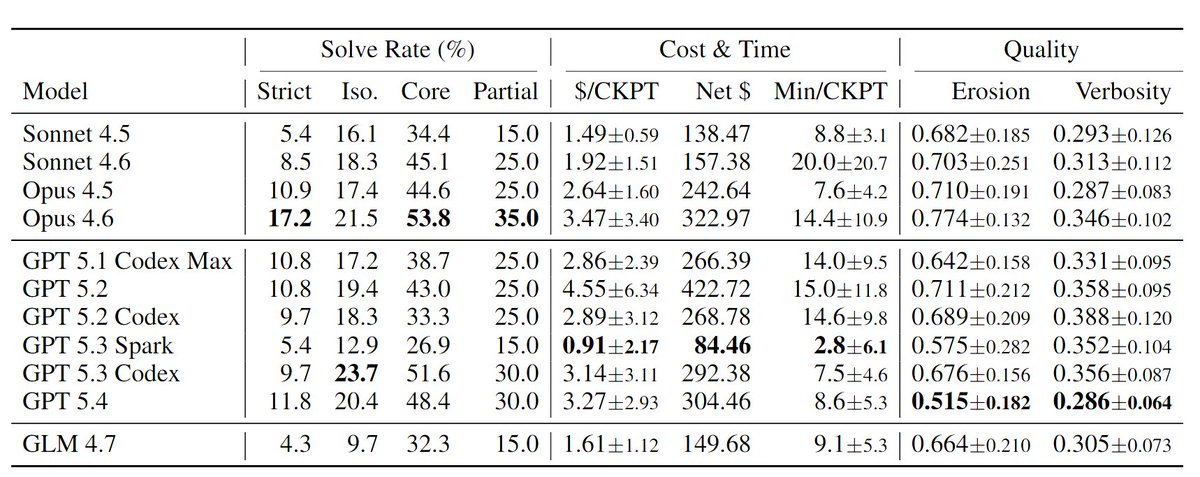
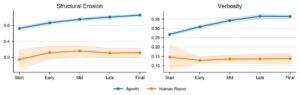
~3mo old model is still SOTA and was +8% vs 5.3-codex on maintainability total anthropic victory Gabe Orlanski (@GOrlanski) We found that agents generate progressively worse code with each iteration. Real developers do not. SlopCodeBench is the only eval that faithfully measures quality degradation on iterative, long-horizon coding tasks. arxiv.org/abs/2603.24755 scbench.ai 🧵 — https://nitter.net/GOrlanski/status/2037560777356238881#m