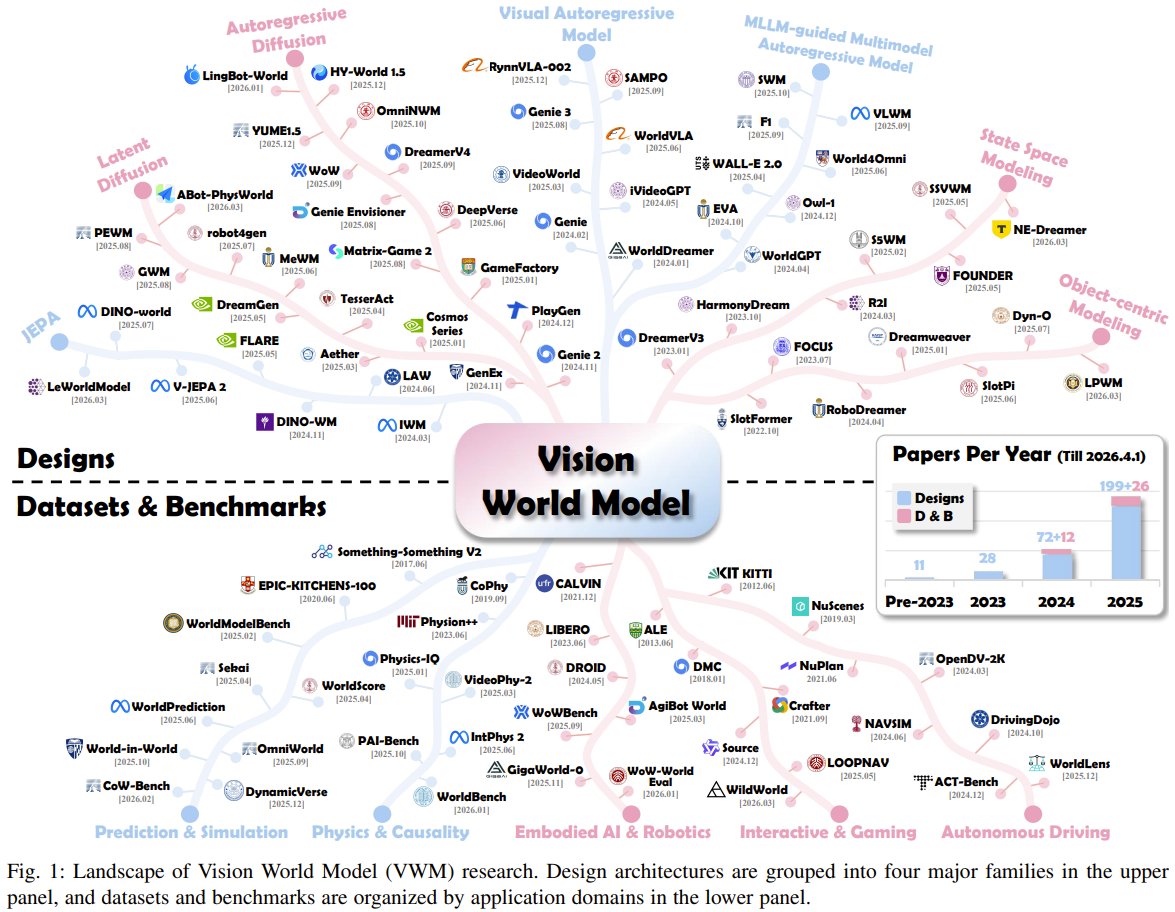
What if AI could learn the world just by watching? Researchers from Beijing Jiaotong, ByteDance, Tencent present a unified framework for Vision World Models: encoding visuals, learning dynamics, simulating outcomes. This survey outperforms fragmented taxonomies, outlining
Unified Vision World Models framework from Beijing Jiaotong, ByteDance, Tencent
By
–