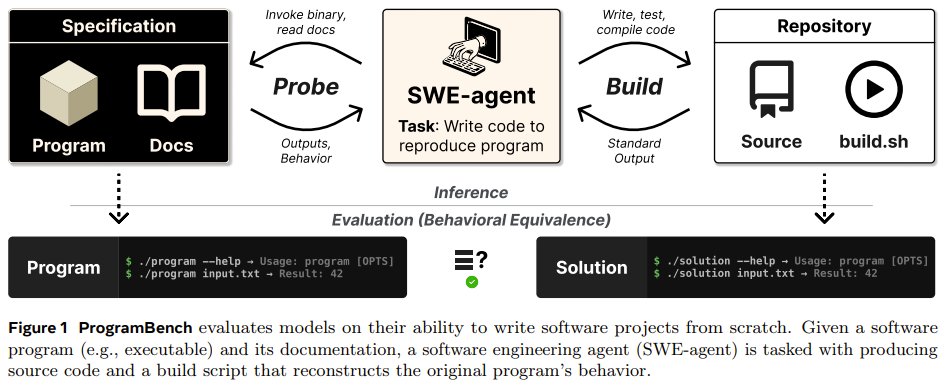
Can AI build an entire software project from scratch, not just fix one bug? Researchers at Meta FAIR, Stanford, and Harvard introduce ProgramBench. This benchmark tests if language-model agents can take a program’s documentation and build a full codebase that behaves
ProgramBench: A New Benchmark for Evaluating AI Agents in Software Development
By
–