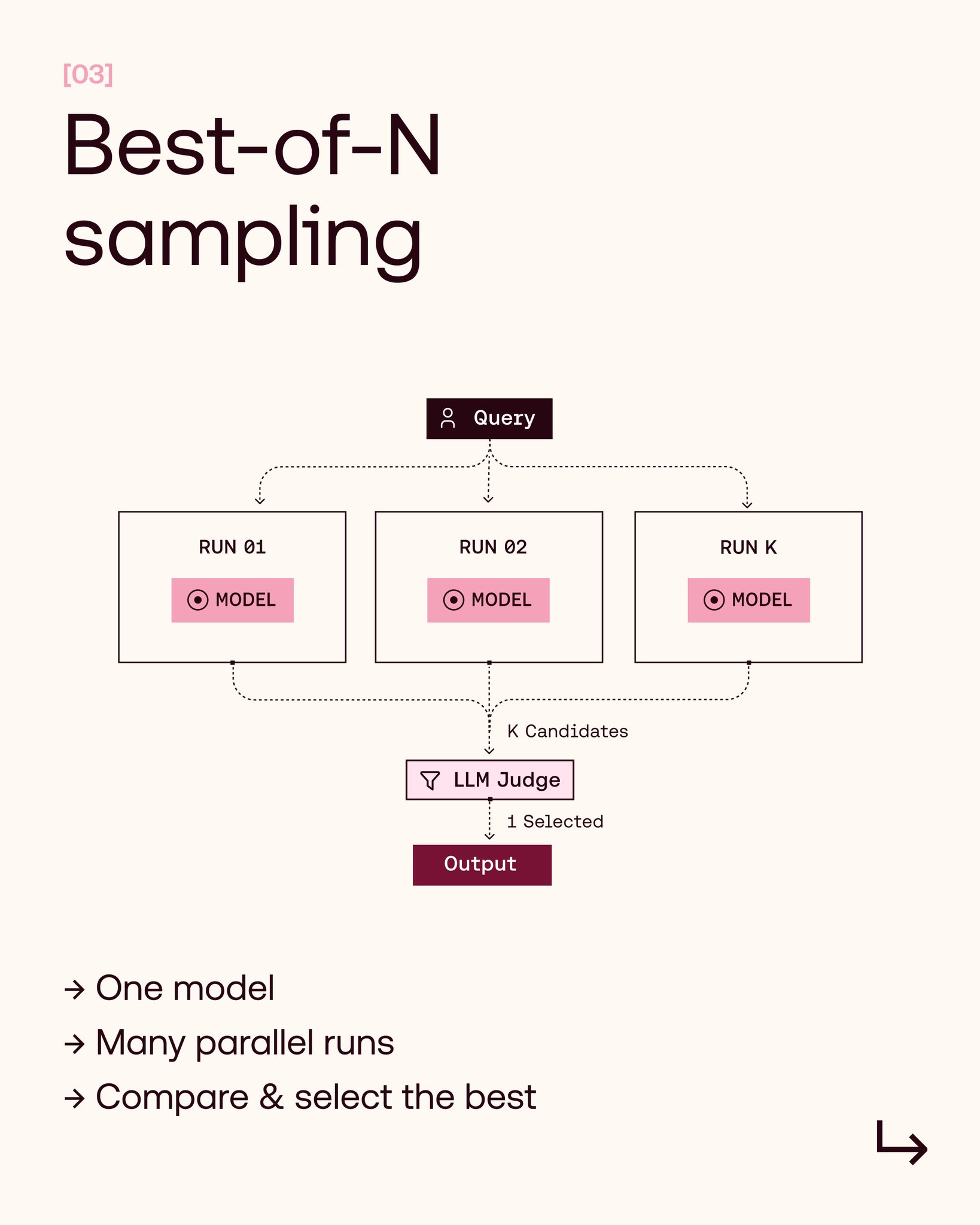
4/5 Best-of-N: Run one agent config N times in parallel → select the best trajectory. Leverages LLMs’ non-determinism – but hinges on a good eval mechanism (we use an LLM-as-a-Judge). Can increase accuracy without linearly increasing latency – but parallel runs can add up $$.