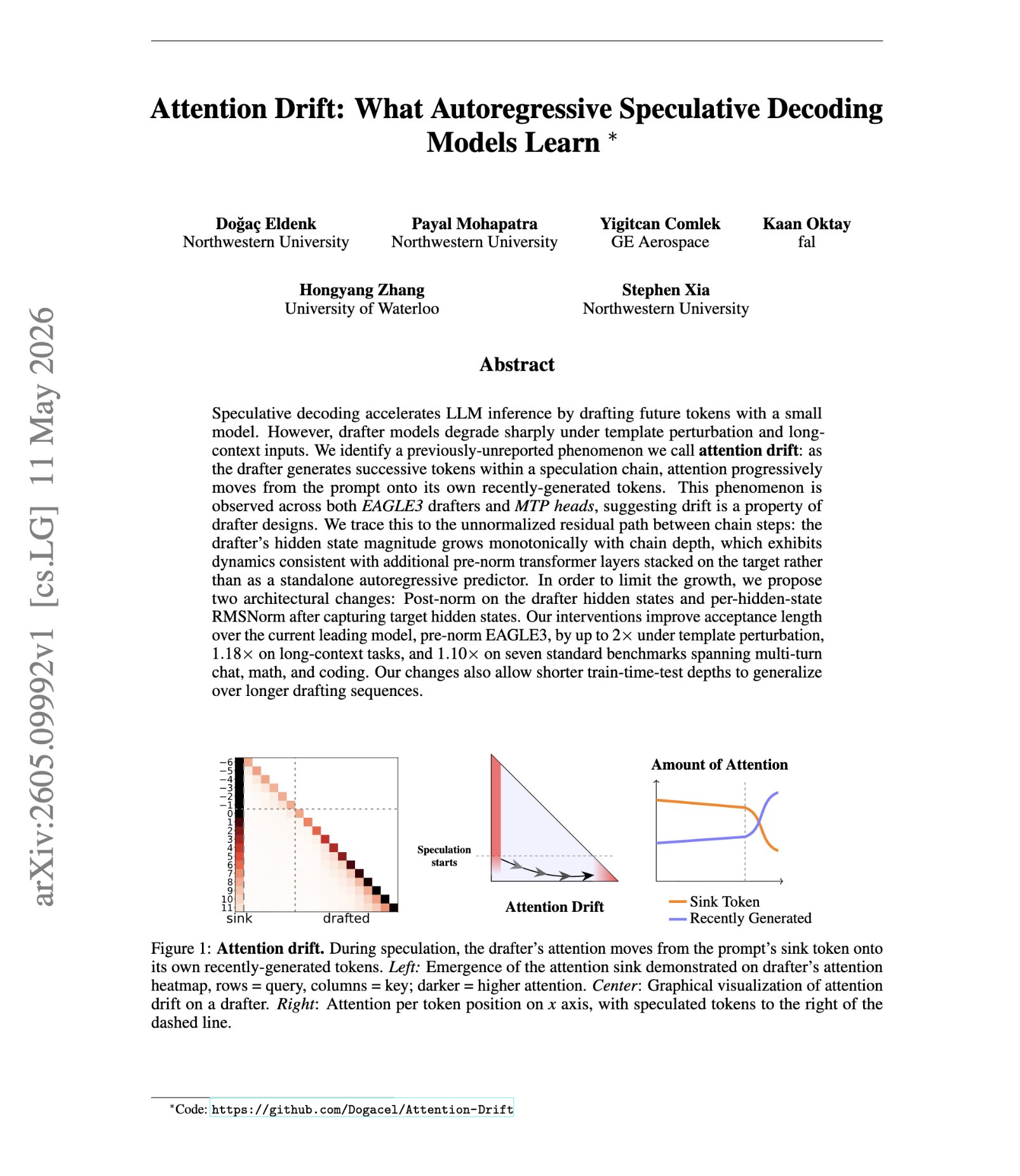
“Attention Drift: What Autoregressive Speculative Decoding Models Learn” Speculative decoding makes LLM inference faster, but drafters break under small template changes and long context. But why? This paper shows that as the drafter predicts more tokens, its attention drifts
Technical Analysis of Attention Drift in Speculative Decoding Models
By
–