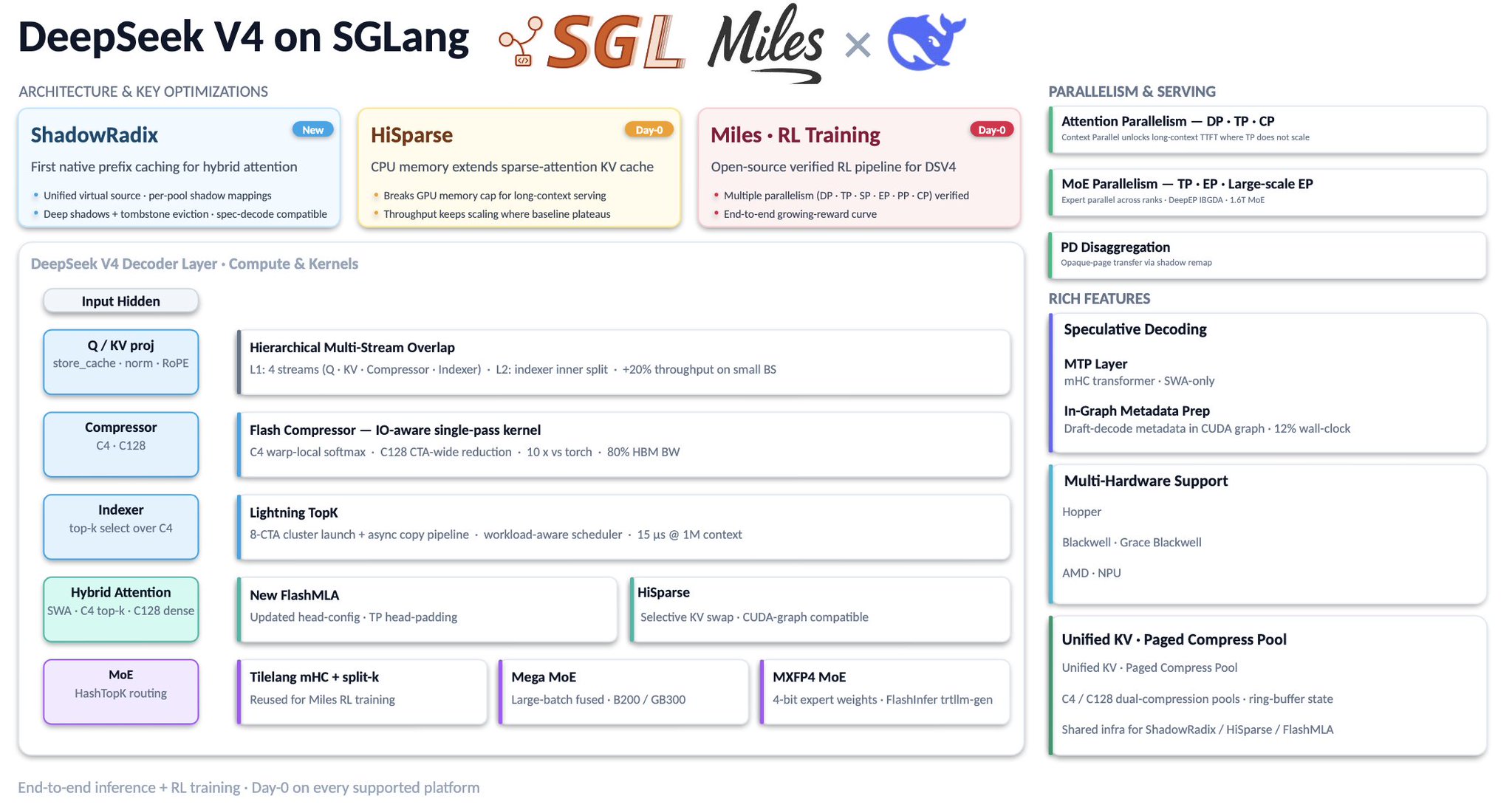
SGLang is hitting 180 tok/s/GPU on DeepSeek-V4 decode with ~1M context on Blackwell. Good to see fast progress in open source DeepSeek-V4 inference on new hardware. This comes from Blackwell-specific optimizations by @lmsysorg that better use the model’s hybrid sparse
SGLang Achieves 180 tok/s/GPU on DeepSeek-V4 with Blackwell Optimizations
By
–