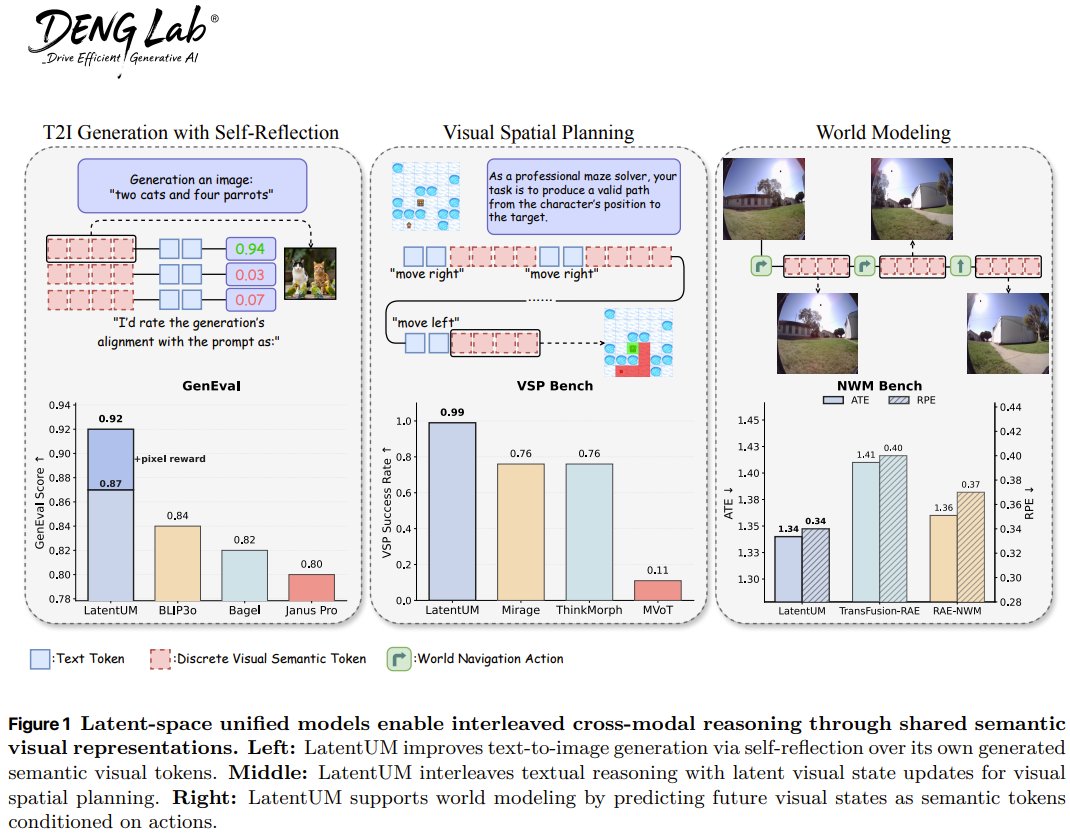
What if an AI could think in pictures and words simultaneously, without the usual translation lag? Researchers from Shanghai Jiao Tong U, Tsinghua U, and UCSD present LatentUM. They built a single model that processes images, text, and actions all in one shared "semantic
LatentUM: AI Model Processes Images Text Actions Simultaneously
By
–