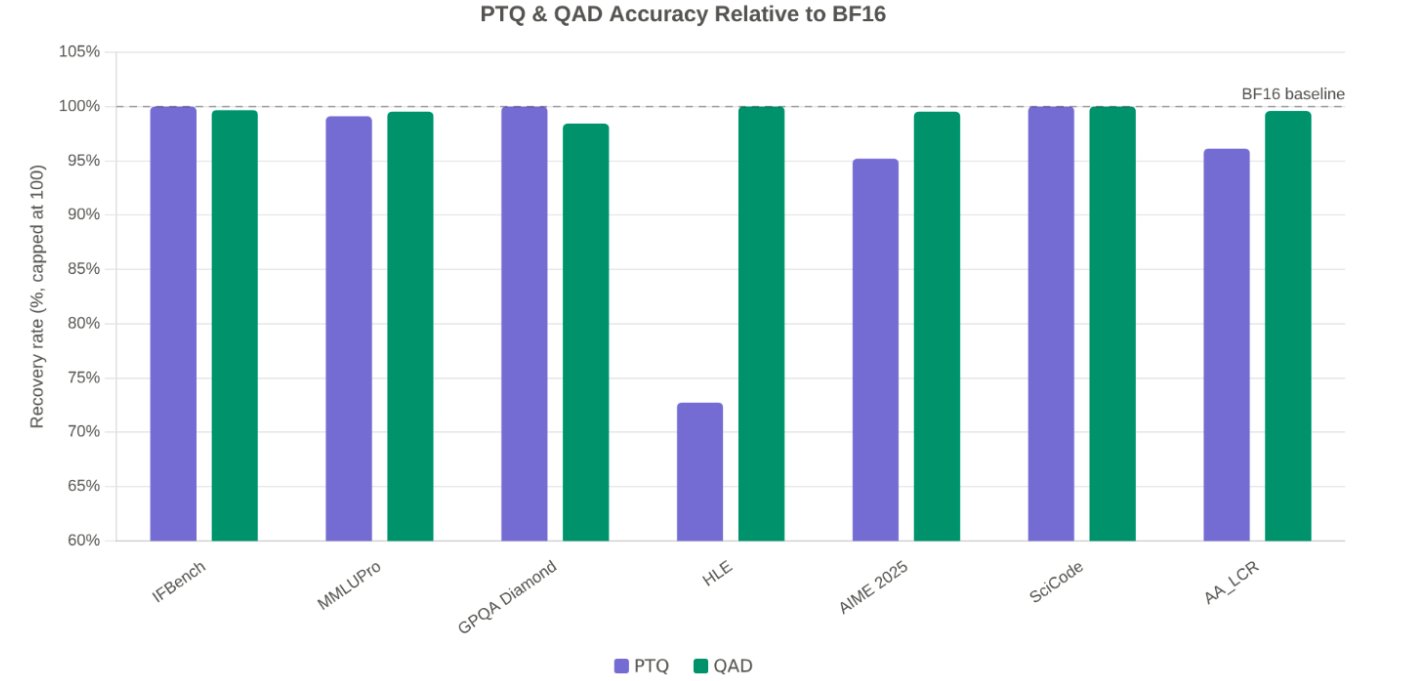
For real agentic workloads (North), short-context calibration wasn't enough. We calibrated AWQ on long internal agentic traces (up to 64k tokens) and added token masking in llm-compressor to exclude repetitive chat templates/tool descriptions from calibration stats. Plus QAD
AWQ Quantization Optimization for Agentic AI Workloads
By
–