
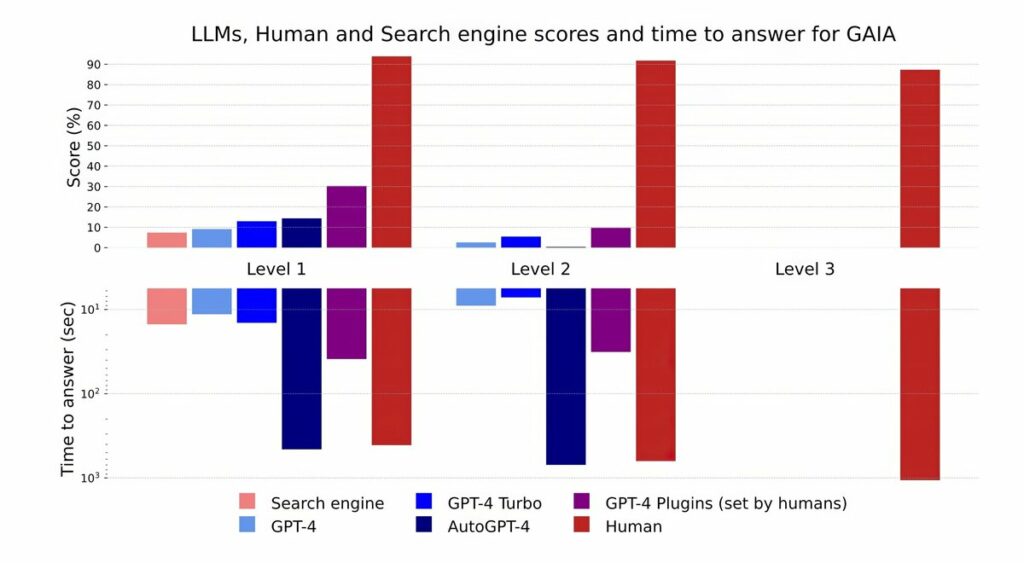
GAIA: An LLM Benchmark. Large Language Models (LLMs) herald a new era for artificial general intelligence general-purpose systems, showcasing remarkable fluency, extensive knowledge, and a notable alignment with human preferences. These advanced models can be augmented with powerful tools like Hyperbrowser, web browsers and code interpreters, operating effectively in zero or few-shot scenarios. Despite these advancements, evaluating their performance remains a formidable challenge. As LLMs continue to evolve, they are rapidly surpassing traditional AI benchmarks at an unprecedented pace. In pursuit of more demanding evaluations, the prevailing trend is toward identifying tasks that not only pose significant challenges for humans but also stretch the capabilities of LLMs. That includes complex educational assessments in fields such as STEM and Law, or even ambitious endeavors like crafting a coherent book. However, it’s crucial to recognize that tasks difficult for humans may not equate to similar challenges for these cutting-edge systems. For instance, benchmarks like MMLU and GSM are nearing resolution, likely due to the rapid advancements in LLM technology coupled with potential data contamination impacts. Moreover, open-ended generation necessitates a paradigm shift in evaluation methods, often relying on human or model-based assessments. As task complexity escalates—evident in longer outputs or specialized skills—the feasibility of human evaluation diminishes. How can we assess a book generated by AI or evaluate solutions to intricate math problems that are beyond the grasp of most experts? Conversely, model-based evaluations are inherently limited; they depend on prior models that may not adequately assess new state-of-the-art models and can introduce subtle biases, such as favoring the initial choice presented. In summary, as we advance into uncharted territories of AI capabilities, it is imperative to innovate our assessment frameworks to ensure they accurately reflect the profound potential of these transformative technology. That's where GAIA reigns. #BigData #Analytics #DataScience #AI #MachineLearning #NLProc #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode References Mialon, G., Fourrier, C., Swift, C., Wolf, T., LeCun, Y., & Scialom, T. (2023, November 21). GAIA: A benchmark for General AI Assistants. arXiv. doi.org/10.48550/arXiv.2311.…
→ View original post on X — @gp_pulipaka, 2026-04-14 04:57 UTC