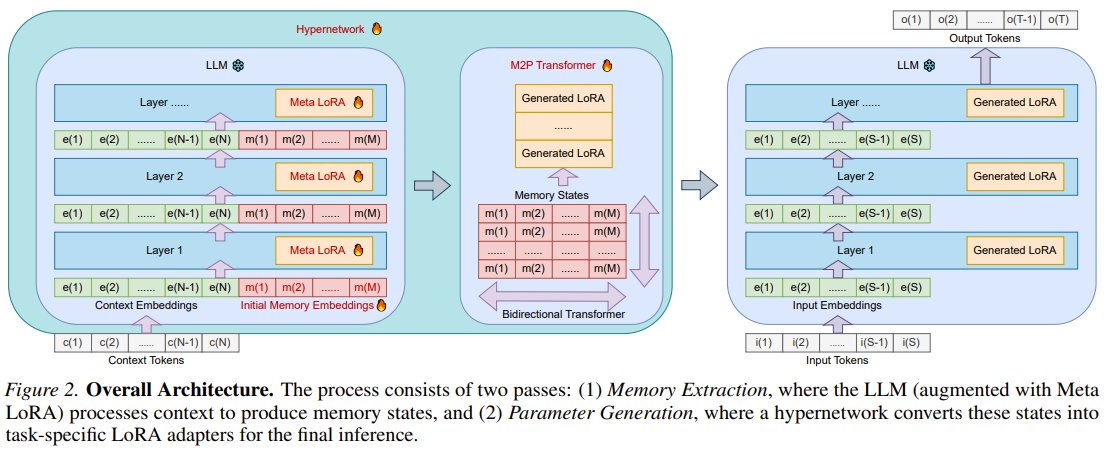
What if LLMs could instantly absorb new context directly into their parameters? Researchers from Peking University, University of Oxford, Technion, and NVIDIA present SHINE! SHINE is an innovative hypernetwork that, in a single pass, generates high-quality LoRA adapters directly from diverse contexts. This effectively bakes temporary contextual knowledge into the LLM’s core parameters, turning it into lasting skill without any traditional fine-tuning. It smartly reuses the LLM's own frozen parameters for efficiency. This breakthrough dramatically cuts down on time, computation, and memory costs compared to supervised fine-tuning (SFT). SHINE outperforms SFT across various tasks, especially in complex question answering by embedding knowledge directly, offering outstanding performance and massive scalability potential. SHINE: A Scalable In-Context Hypernetwork for Mapping Context to LoRA in a Single Pass arXiv: arxiv.org/abs/2602.06358 GitHub: github.com/Yewei-Liu/SHINE Hugging Face: huggingface.co/collections/Y… Our report: mp.weixin.qq.com/s/sy1L2RoWu… 📬 #PapersAccepted by Jiqizhixin
→ View original post on X — @jiqizhixin, 2026-04-06 01:11 UTC