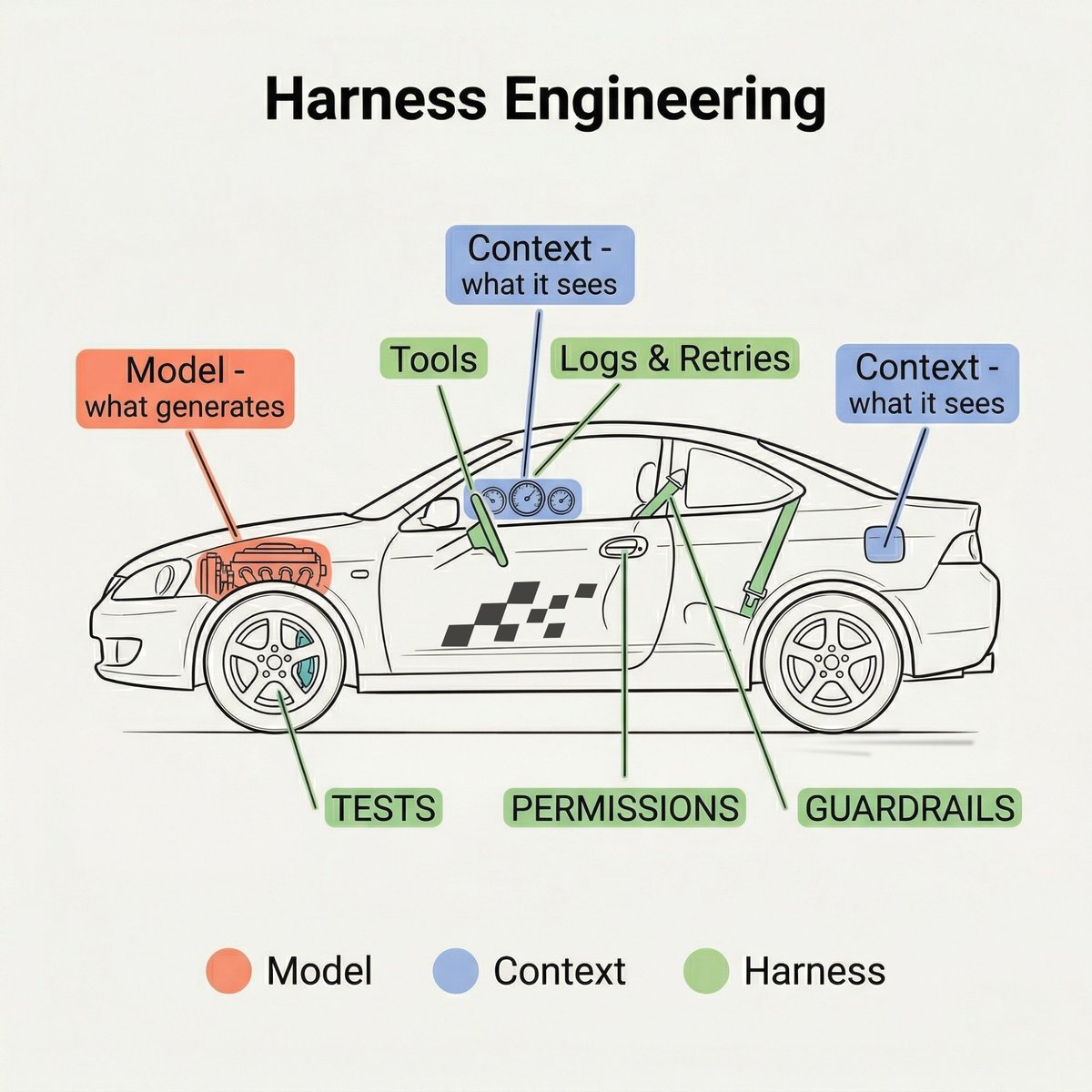
I let Claude Code loop for 45 minutes while I was at the gym. Came back. It told me the feature was done. It wasn't. It hadn't even run the tests. Not because the model is dumb. Because I wrapped it in nothing but a loop and a dream. That's harness engineering in one sentence. And no, it's not prompt engineering with a fancier name. The model is the engine. Context is the fuel. The harness is the rest of the car. Steering. Brakes. Lane boundaries. Warning lights. Tools, permissions, tests, retries, guardrails. Engine + fuel but not strong parts in it = dangerous car. So I stopped tuning the engine and started building the car around it. In every skill file (Claude Code, Claude Co-work), I added one last step. After each interaction, the agent reflects on what I liked, what I edited, what failed. Then it updates its own skill to be better next time. Token usage dropped (a lot). Output quality went up. Compounding improvement with zero extra effort from me. LangChain did something similar at a bigger scale. Changed only the harness on a coding agent. Same model. Went from outside the top 30 to top 5 on a benchmark. Same engine, completely different results, just because the car around it was better. Next time your agent breaks, don't blame the model. Fix the car. P.S. Do your agents learn from their mistakes, or do they keep making the same ones?
Harness Engineering: Building Better AI Agent Systems
By
–