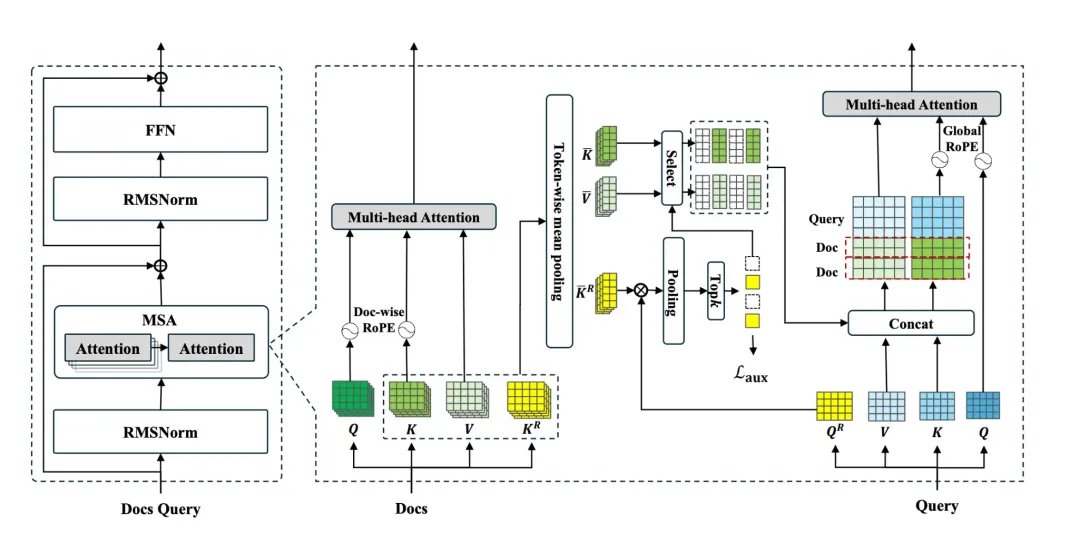
Can AI models finally process context the size of a lifetime? Evermind, Shanda Group, and Peking University present Memory Sparse Attention (MSA)! This new framework gives AI a massively scalable, end-to-end trainable long-term memory. It uses an innovative sparse attention architecture and other techniques to handle hundreds of millions of tokens with linear efficiency, maintaining exceptional precision. MSA processes 100M tokens on 2xA800 GPUs with less than 9% precision degradation from 16K. It significantly outperforms frontier LLMs, SOTA RAG systems, and leading memory agents in long-context benchmarks, paving the way for lifetime-scale AI memory. MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens Code: github.com/EverMind-AI/MSA Paper: zenodo.org/records/19103670 Our report: mp.weixin.qq.com/s/FHJA4kALc… 📬 #PapersAccepted by Jiqizhixin
→ View original post on X — @jiqizhixin, 2026-04-02 14:25 UTC