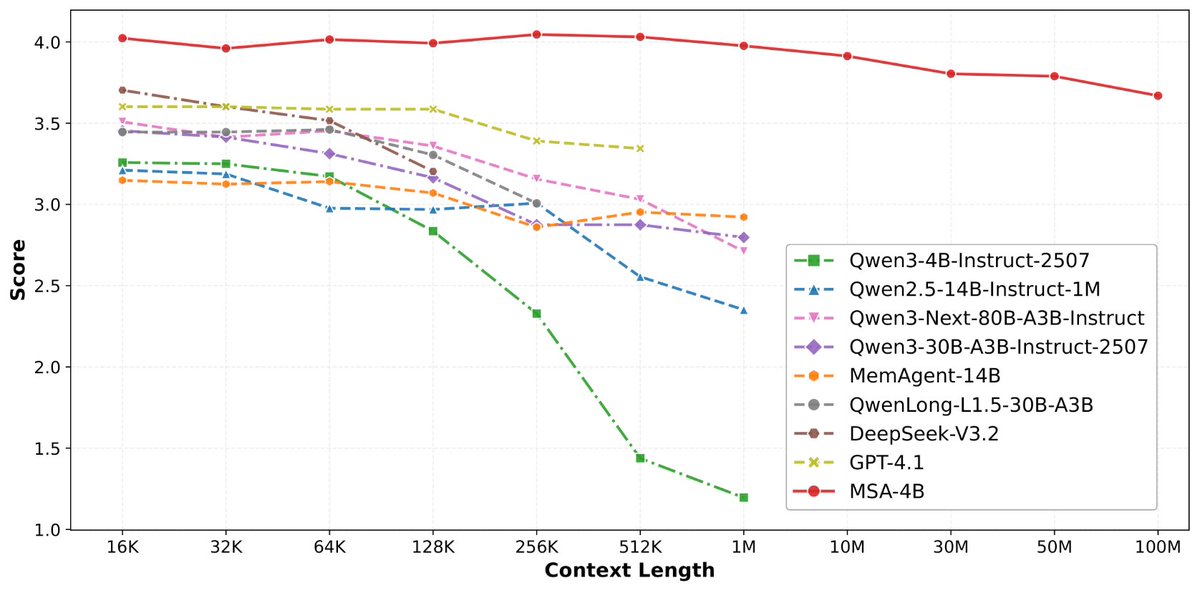
10 天前我们发了 MSA, Memory Sparse Attention。 刚好,上周 Google 专门发了一篇博客,把 Titans + MIRAS 两篇论文打包,主题就叫「Helping AI have long-term memory」。 research.google/blog/titans-… 两条独立的研究路线,得出了同一个结论: AI 的记忆不能靠外挂,必须原生长在模型里。 但怎么「长」,路线完全不同。 Google 的思路是加模块。 在 Transformer 旁边接了一个 Memory MLP,用「惊讶度」指标决定什么值得记, 越意外的信息越值得存。再用自适应衰减机制学会遗忘,防止记忆爆炸。 本质上,是给模型装了一个外置海马体。短期记忆走注意力,长期记忆走 Memory MLP,两条通路并行。 MSA 的思路是改机制。 不加新模块,直接改造注意力本身。核心是一个可扩展的稀疏注意力架构,复杂度是线性的,记忆翻 10 倍,计算成本不会指数爆炸。用 document-wise RoPE 让模型天然理解「这段记忆来自哪里、什么时候产生的」。 用Memory Interleave 让散落在不同文档里的记忆碎片能被串起来做多跳推理。 最关键的一点:MSA 的记忆路由器和生成任务是端到端联合训练的。不像 RAG 的检索和生成是两个割裂的系统,优化目标互相打架。 一个是给大脑装外置硬盘,一个是让大脑自己进化出海马体。 结果呢? · 4B 参数的 MSA 模型,从 16K 扩到 1 亿 token,精度衰减不到 9% · 在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑,这是创业公司买得起的成本 往后退一步看,这件事更大的意义是: 当 Google 把积累了一年多的记忆研究拿出来做重点战略宣传的时候,这个方向就不再是少数人的赌注,而是行业共识。 RAG 是第一代记忆(外挂笔记本)。 Titans 是第二代记忆(外置硬盘)。 MSA 是第三代记忆(原生海马体)。 「记忆」是 AI 的下一个基础设施。这条路,我们会一直走下去。 未来,可能真有一种服务叫做「Memory as a servicey」。 艾略特 (@elliotchen100) 论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 github.com/EverMind-AI/MSA — https://nitter.net/elliotchen100/status/2034479369855590660#m
→ View original post on X — @elliotchen100, 2026-03-29 06:12 UTC