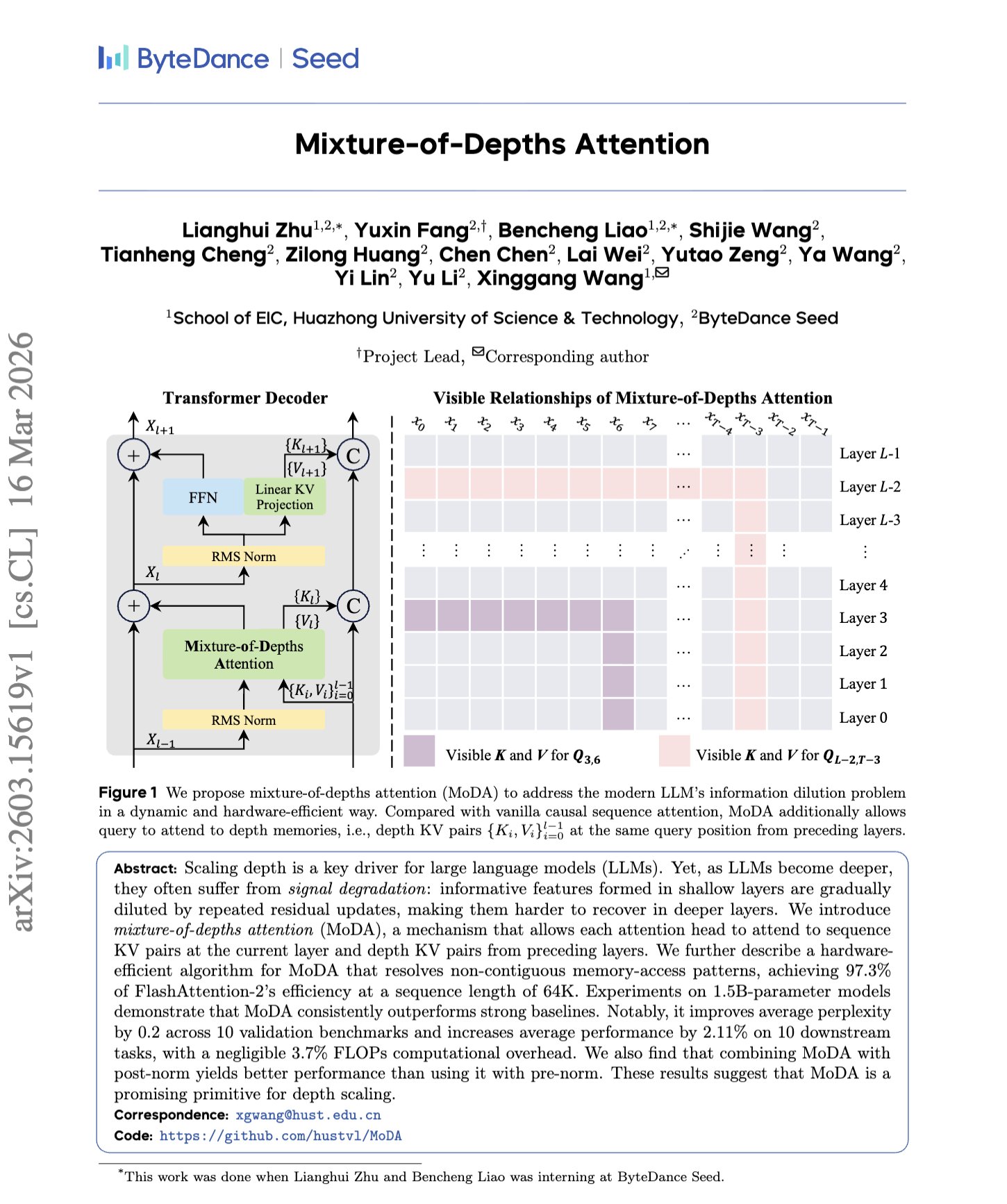
"Mixture-of-Depths Attention" This paper teaches a Transformer to attend not just across tokens, but also to depth KV from its earlier layers. That helps recover shallow-layer signals that standard residual stacking tends to dilute, improving performance with only a small extra
Mixture-of-Depths Attention: Transformer Architecture Innovation
By
–