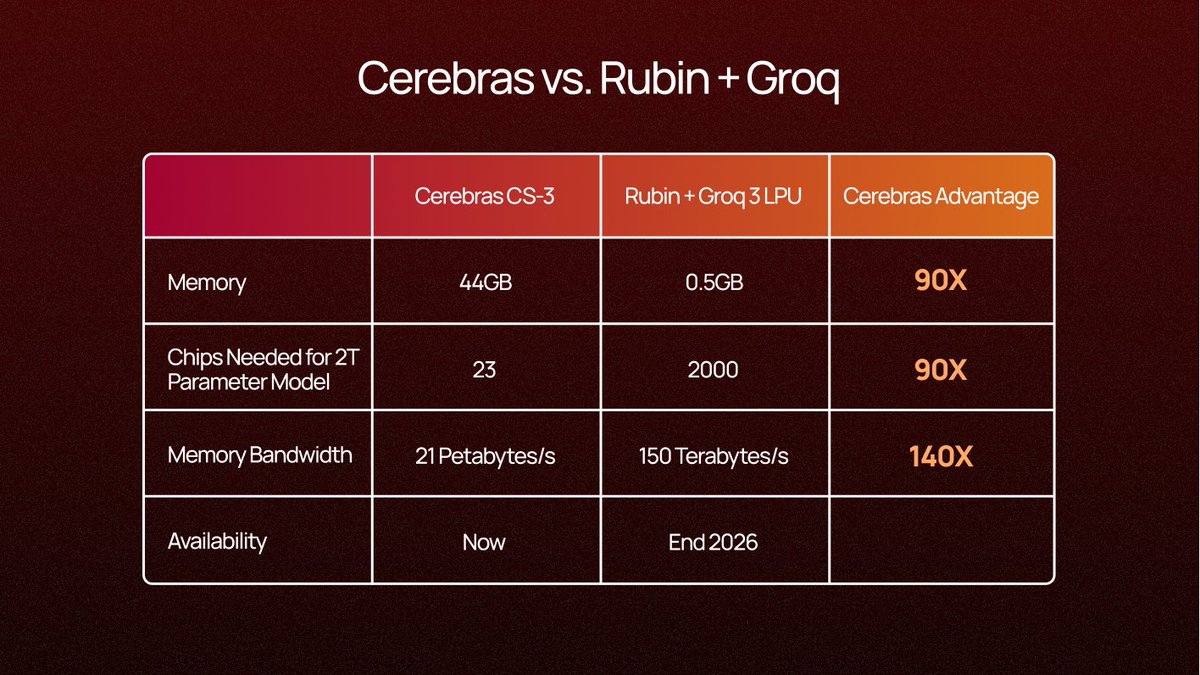
Problem solved. ✅ Andrew Feldman (@andrewdfeldman) NVIDIA's biggest GTC announcement was a $20 billion bet on the same problem we solved 6 years ago. Their next-gen inference chip – not available yet – has 140x less memory bandwidth than @cerebras. To run a single 2 trillion parameter model, you need 2,000+ Groq chips. On Cerebras, that's just over 20 wafers. Even paired with GPUs, Groq maxes out at ~1,000 tokens per second. We run at thousands of tokens per second today. And every day. In production now. Why? When you connect 2,000 chips together, every interconnect has latency. Every cable has overhead. It doesn't matter what your memory bandwidth is on paper if you're bottlenecked by the wiring between thousands of tiny chips. We solved this with wafer scale. One integrated system. Little interconnect tax. Jensen told the world that fast inference is where the value is. He’s right – it’s why the world’s leading AI companies and hyperscalers are choosing Cerebras. — https://nitter.net/andrewdfeldman/status/2034015373595672594#m
Cerebras Wafer Scale Advantage Over NVIDIA Groq Inference Chips
By
–