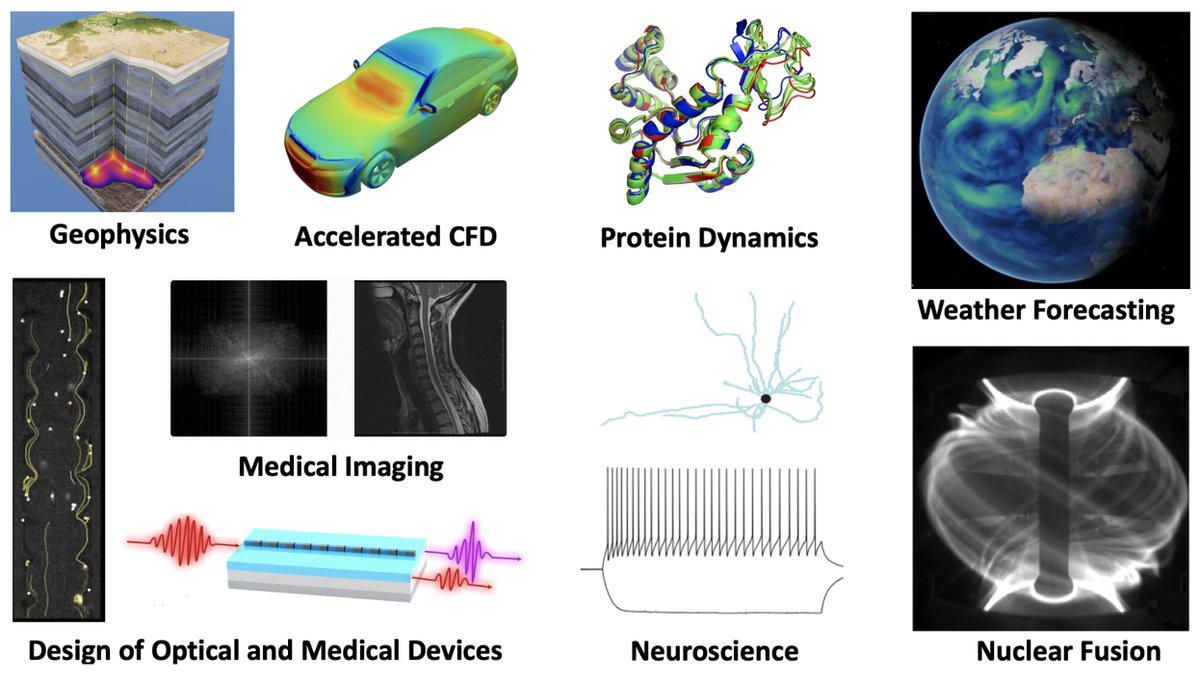
What if you could run a million simulations in the time it takes to run one? Neural operators are making this a reality. These neural networks learn to approximate the physics behind conventional simulations and then produce new solutions almost instantly. The result? Better-performing chips, smarter fusion reactors, faster drug discovery. A new neural operator is trained for each design problem. The design process unfolds as follows: 1. The problem is defined. For example, optimizing the layout of a computer chip to minimize hot spots that arise during operation and can lead to device failure. 2. The parameter space is defined. In the above example, this could be the range of possible layouts and connections between chip components. 3. Hundreds or thousands of conventional simulations are run to sample the parameter space. These simulations can be very computationally intensive, requiring a supercomputer in some cases. 4. The neural operator is trained on those simulations. Crucially, while the training simulations use discrete grids, neural operators learn continuous solutions. This means they can be trained on lower-resolution simulations and still produce accurate results at higher resolutions, saving even more compute. 5. The trained network evaluates candidate designs almost instantly, enabling rapid optimization across the parameter space. 6. The solution is verified with a conventional simulation. In practice, these checks are run periodically throughout the process to keep the neural operator honest. By replacing the bulk of expensive simulations with near-instant neural operator evaluations, engineers can explore vast design spaces that were previously out of reach. Yet another example of how neural networks beyond LLMs are quietly transforming science and engineering.
→ View original post on X — @animaanandkumar, 2026-02-23 19:00 UTC