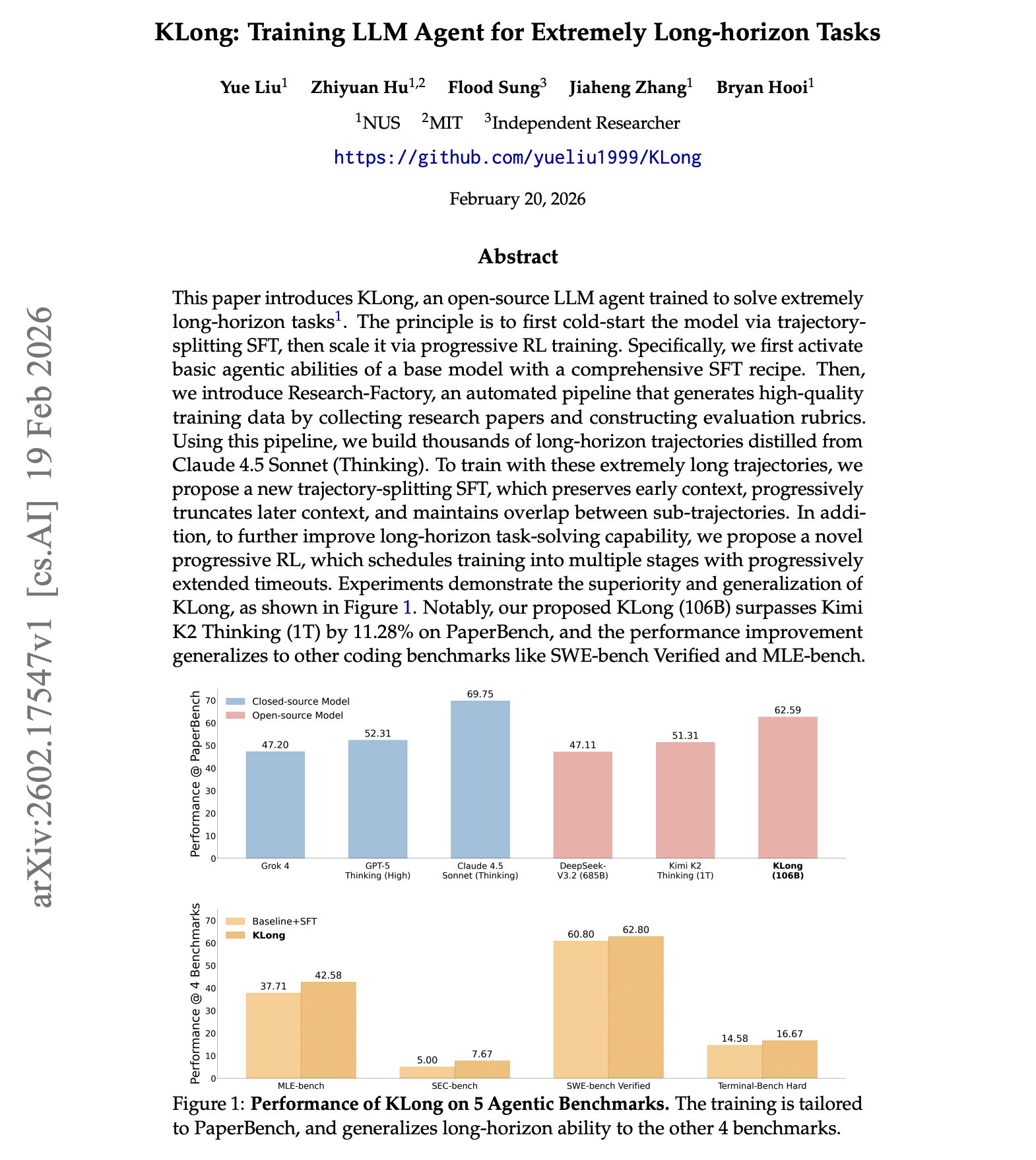
Training LLM agents for extremely long-horizon tasks remains an open challenge. Most agent training pipelines struggle with extended-duration trajectories. Context gets lost, rewards are sparse, and the learning signal degrades over long sequences. KLong tackles this with a
KLong: Training LLM Agents for Extremely Long-Horizon Tasks
By
–