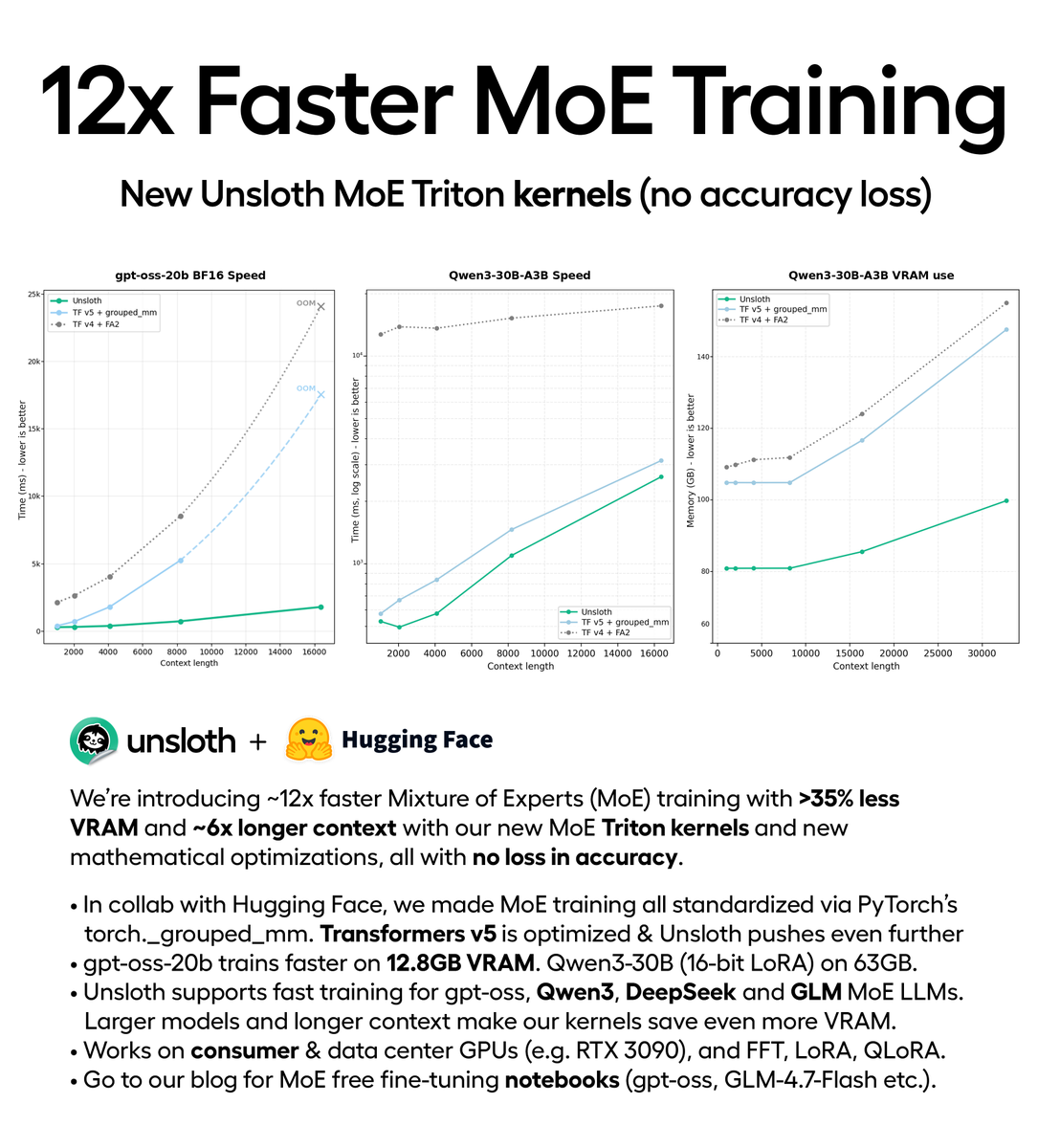
You can now train MoE models 12× faster with 35% less VRAM via our new Triton kernels (no accuracy loss). Train gpt-oss locally on 12.8GB VRAM. In collab with @HuggingFace, Unsloth trains DeepSeek, Qwen3, GLM faster. Repo: github.com/unslothai/unsloth Blog: unsloth.ai/docs/new/faster-m…
→ View original post on X — @abhi1thakur, 2026-02-10 15:25 UTC