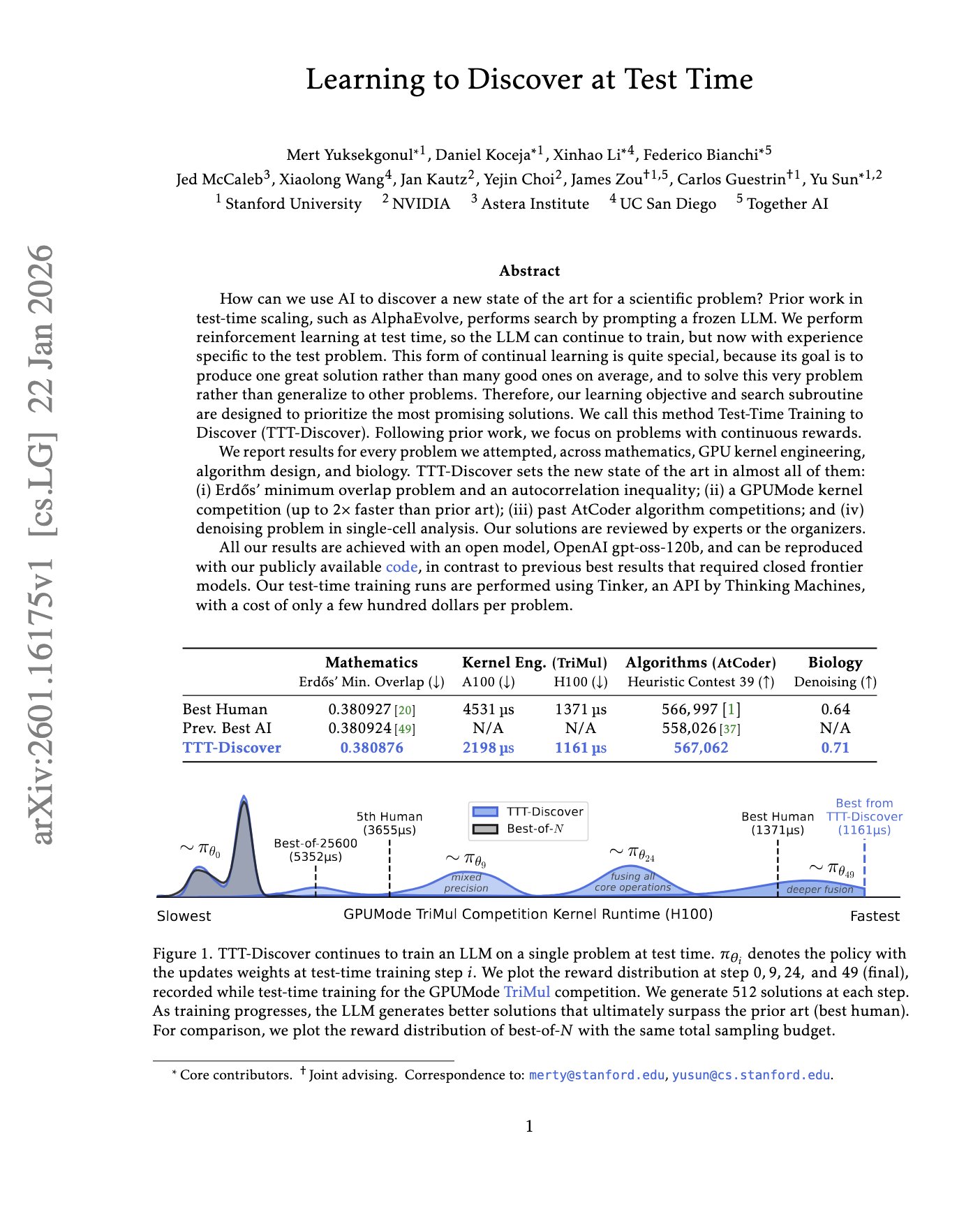
Learning to Discover at Test Time This paper TTT-Discover shows that by replacing best-of-N prompting with RL at test time on a continuous verifiable reward (via LoRA), it can learn from its own attempts and reliably push past the prior performance. The “learn-while-solving”
Test-Time Learning: RL Discovers Solutions During Inference
By
–