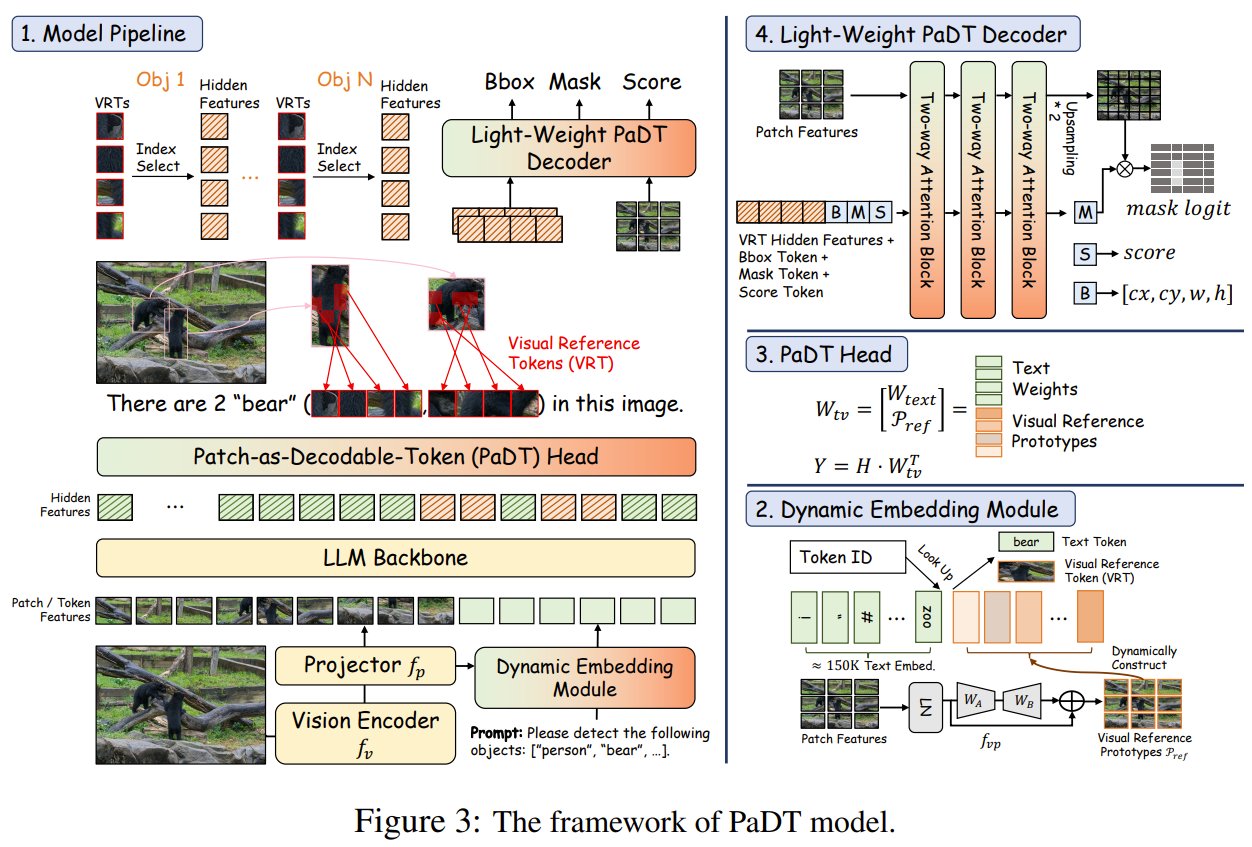
Ever wonder if an AI could do more than just describe an image and actually show you where things are? PaDT (Patch-as-Decodable Token) is a unified paradigm enabling Multimodal Large Language Models (MLLMs) to directly generate visual outputs like detection boxes and
PaDT: MLLMs Generate Visual Detection Outputs Directly
By
–