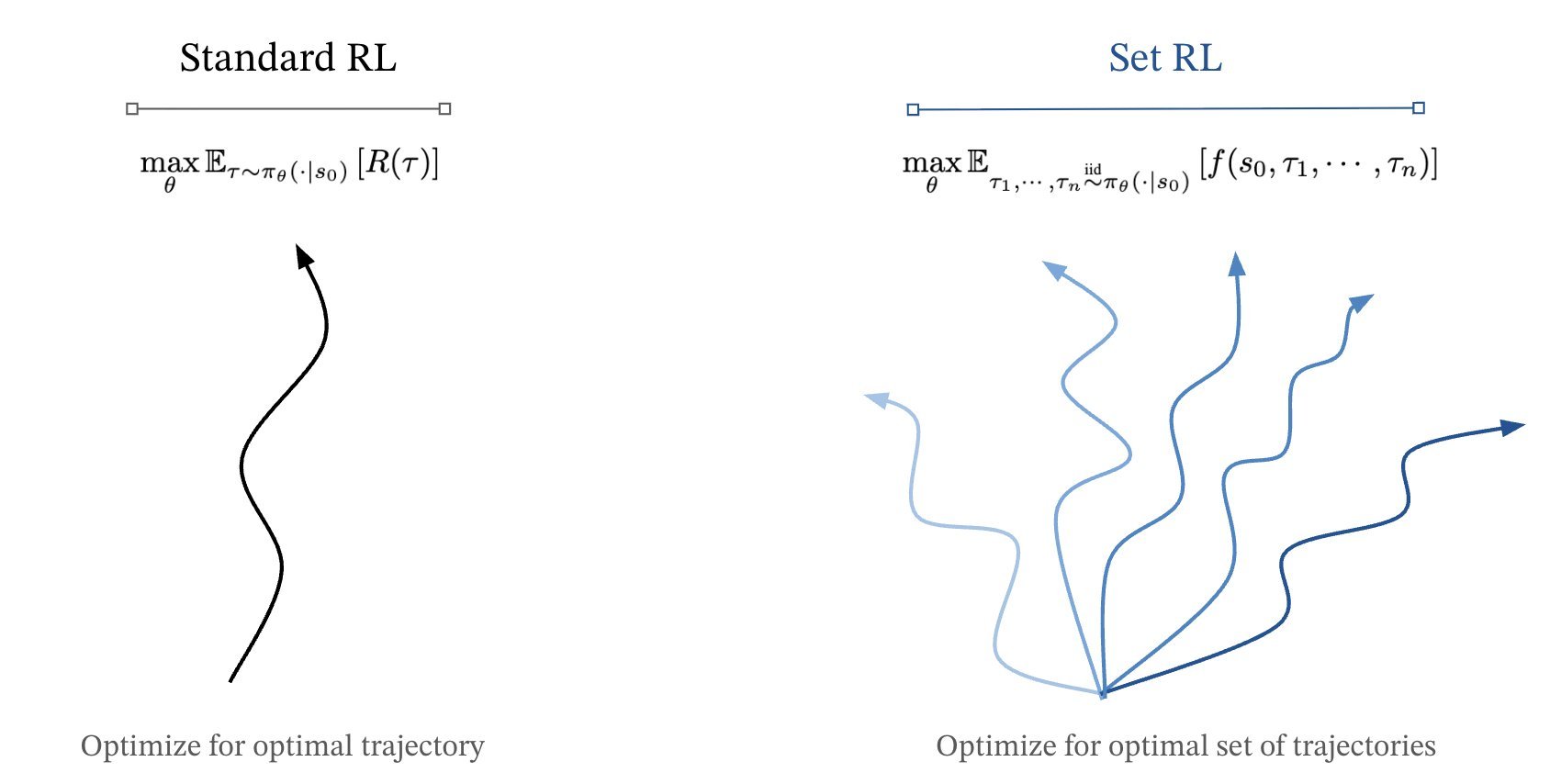
We have always been using 1 RL trajectory for training. Why not use more? In this research: Polychromic Objectives for RL, they train their model on sets of trajectories and reward both success & diversity, so the agent keeps MULTIPLE strategies alive all at once.
Multiple RL Trajectories Improve Agent Strategy Diversity
By
–