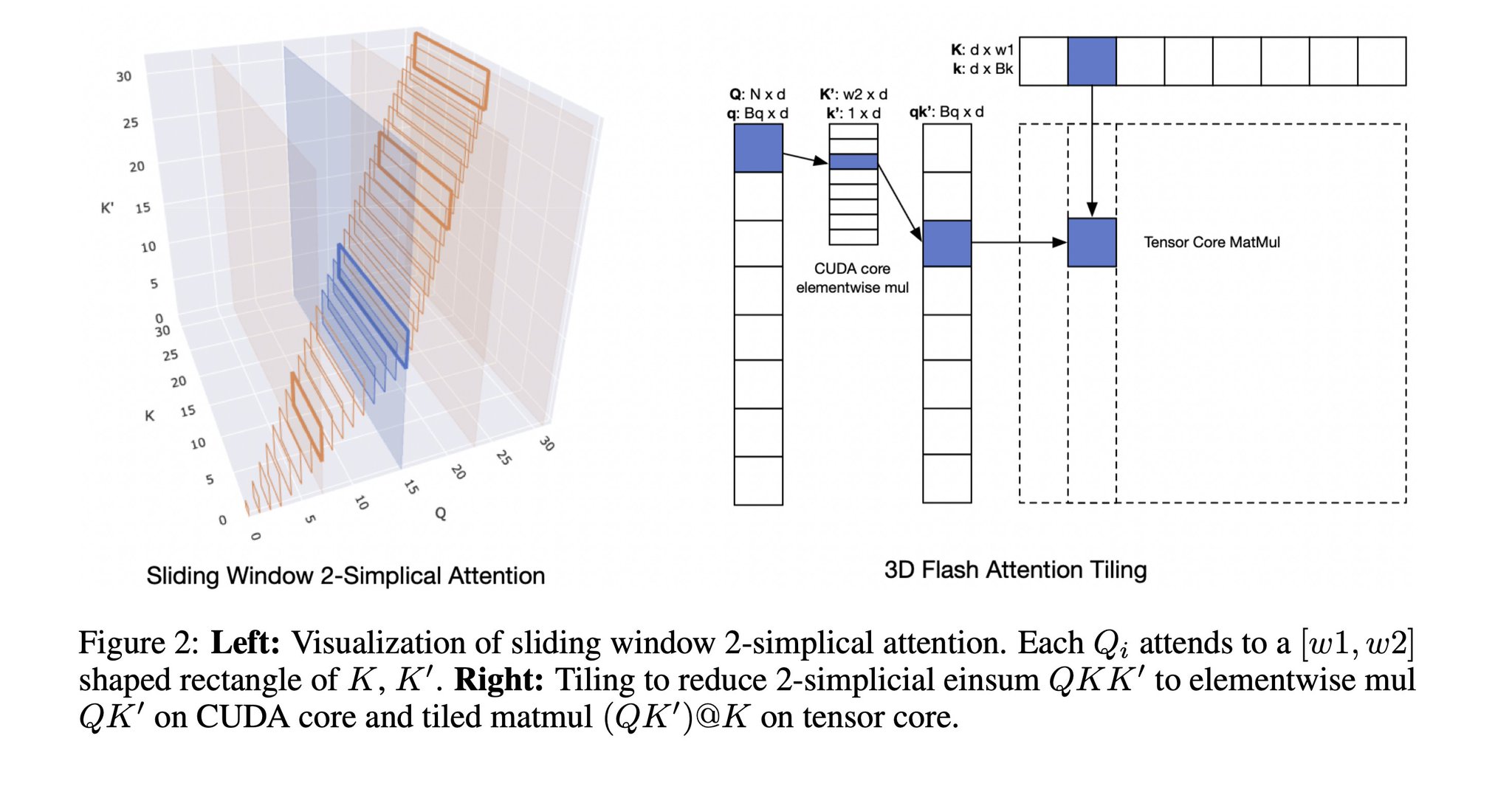
what if attention operated in 3D? This paper introduces trilinear (2-simplicial) attention, and it might have just rewrite the current transformer scaling law by squeezing out the same accuracy with far fewer tokens.
Trilinear Attention Rewrites Transformer Scaling Laws
By
–