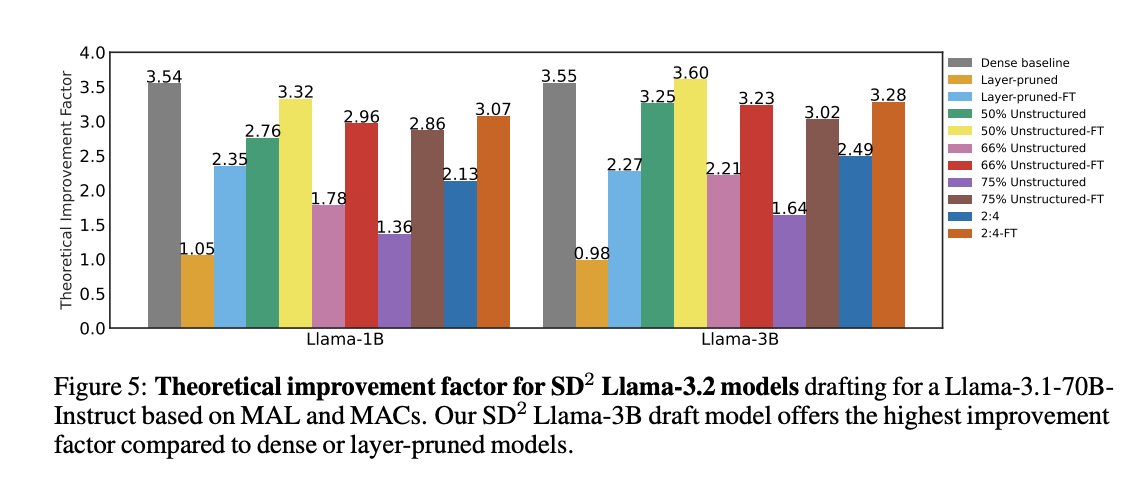
The results: – 1.59× higher Mean Accepted Length (MAL) than layer-pruned draft models
– 43.87% fewer MACs (Multiply-Accumulate operations) than dense draft models
– Only 8.36% reduction in MAL vs. dense models — a strong tradeoff for efficiency
Draft Model Pruning Achieves 43% Fewer MACs with Strong Performance
By
–