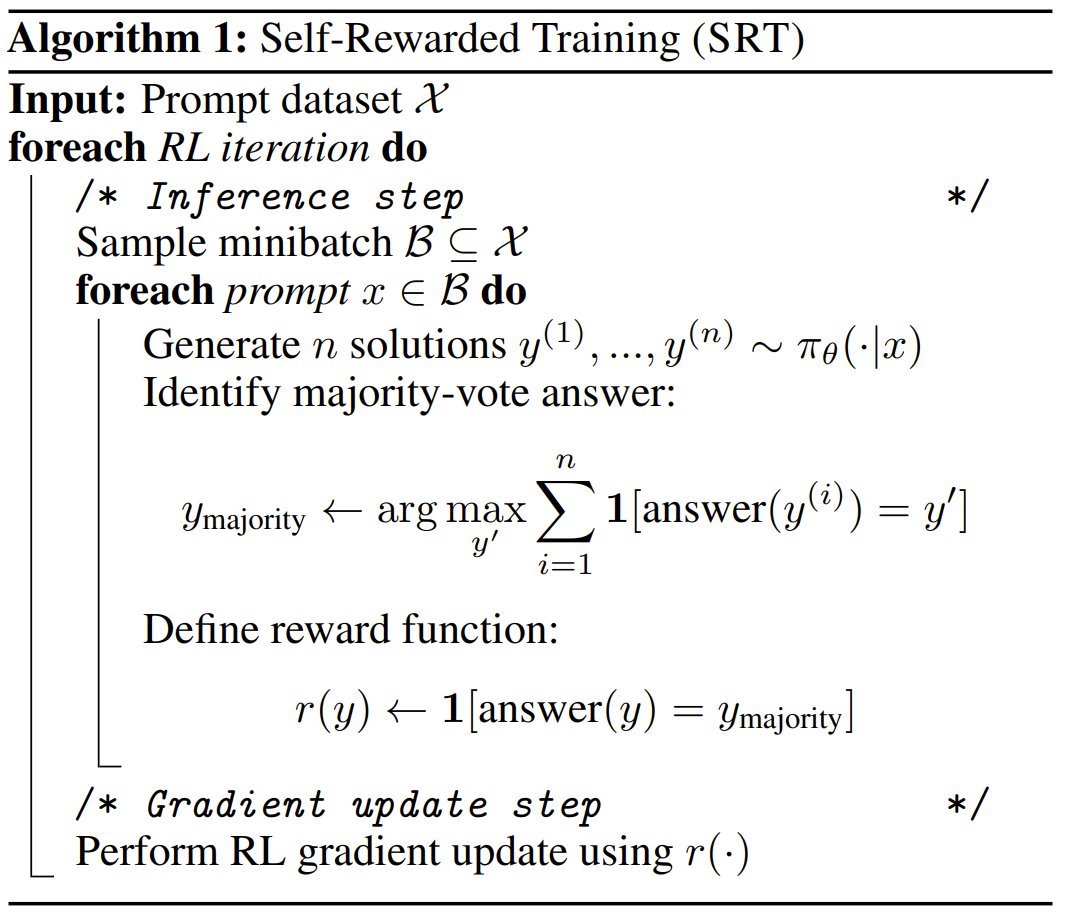
Scaling LLMs through Reinforcement Learning (RL) usually needs human-crafted verifiers or gold answers, which limits scalability. Can models train themselves, without external supervision? This paper propose: using the model’s own self-consistency (i.e., agreement across
Self-Consistency Training for LLM Scaling Without Human Supervision
By
–