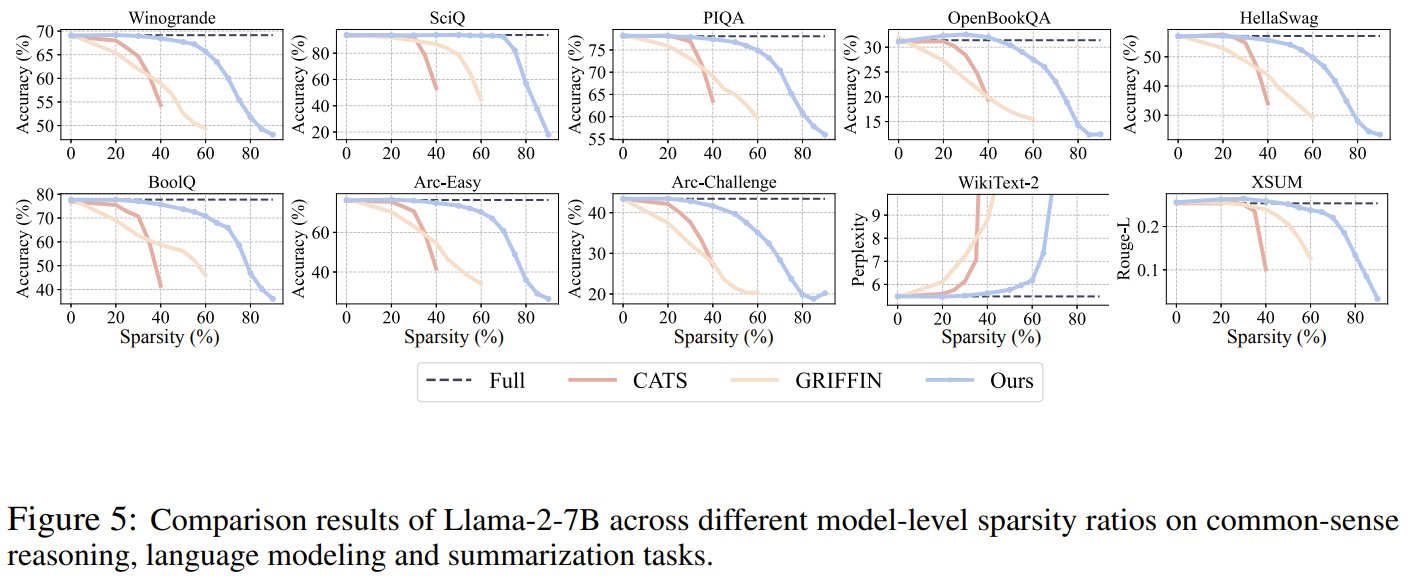
What if your LLM ran twice as fast—with zero retraining?
R-Sparse slashes compute by 50% using a clever trick: skip the unimportant math without guessing what to skip. No tuning, no ReLU, no problem. It’s efficient inference, reimagined for the edge.
R-Sparse: 50% faster LLM inference without retraining
By
–