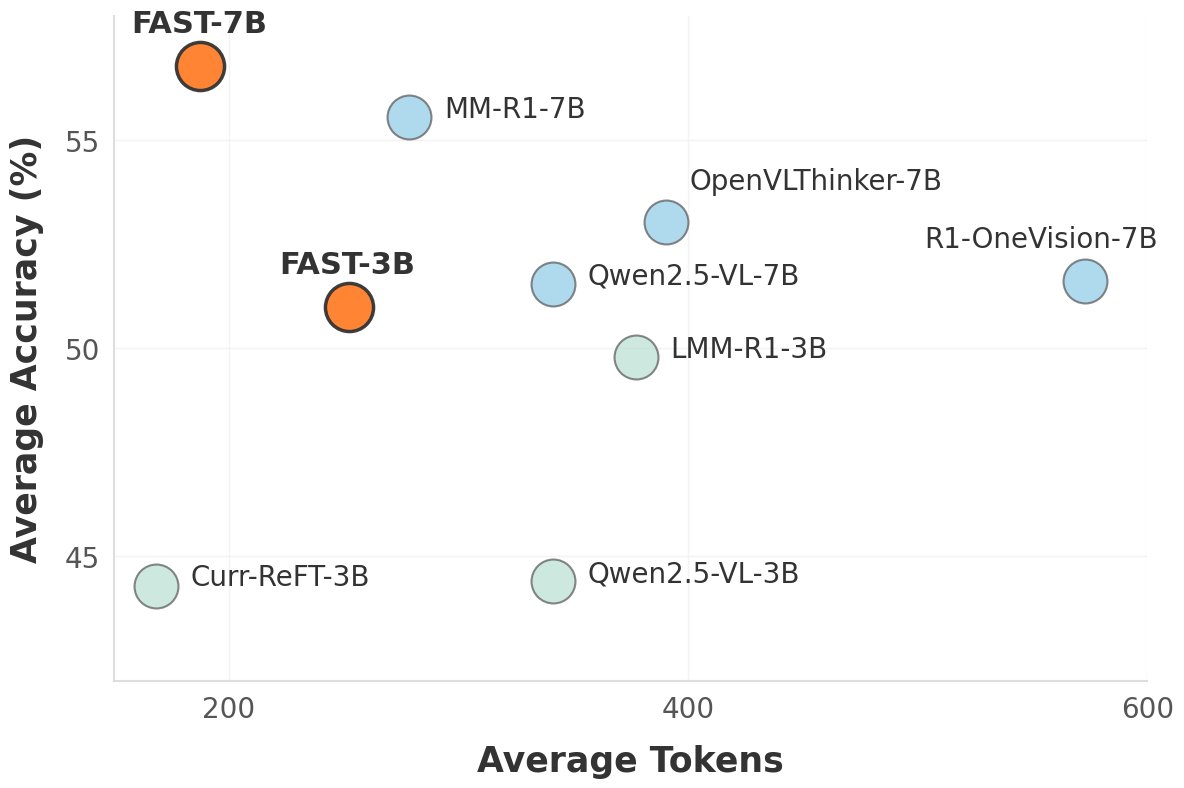
Multimodal LLMs often "overthink"—producing long, verbose answers even for simple visual questions FAST (Fast-Slow Thinking for LVLMs) achieves SOTA accuracy while slashing token usage +10% accuracy over baselines Up to 67% fewer tokens used Trending on alphaXiv
FAST Framework Boosts Multimodal LLM Accuracy While Reducing Tokens
By
–