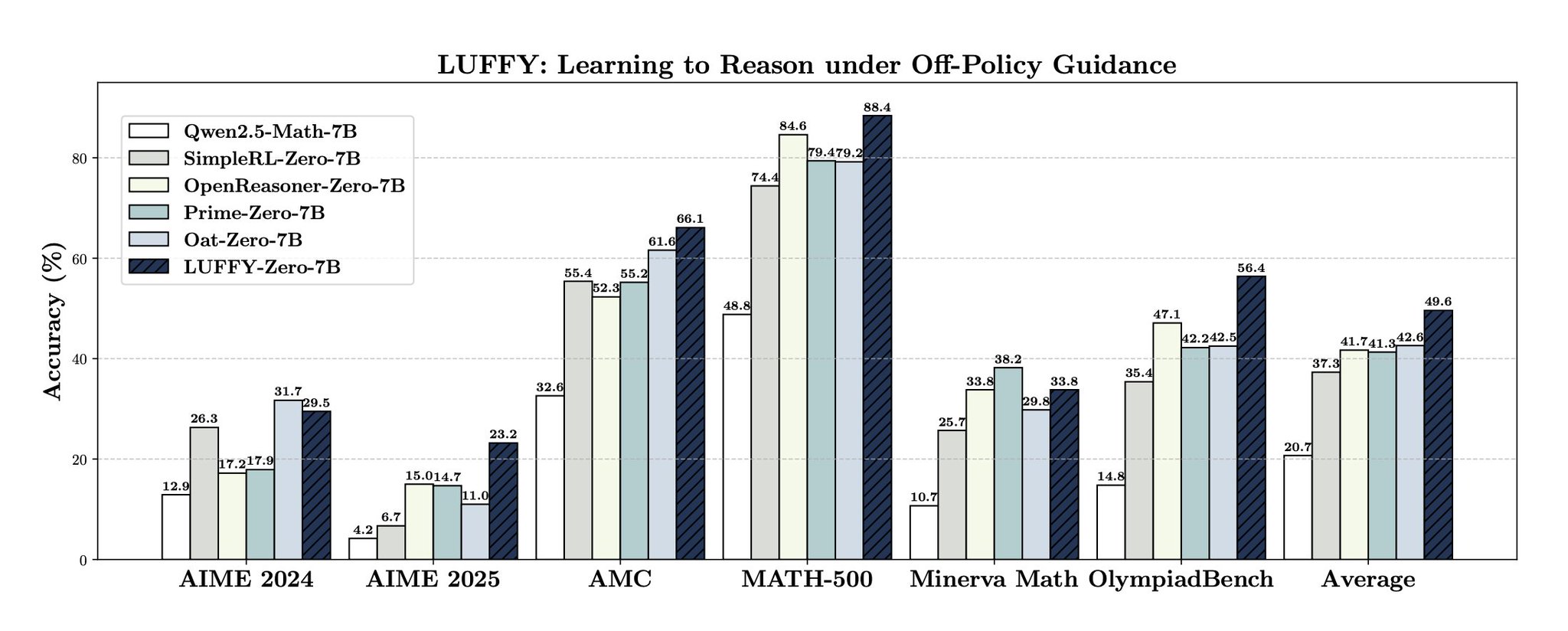
LLMs still struggle with deep reasoning LUFFY is a new framework bridging imitation and exploration by injecting off-policy guidance (like DeepSeek-R1) into zero-RL Boosts math reasoning by 7 points Improves weaker base models like Llama and Qwen Trending on alphaXiv
LUFFY Framework Boosts LLM Math Reasoning by Seven Points
By
–