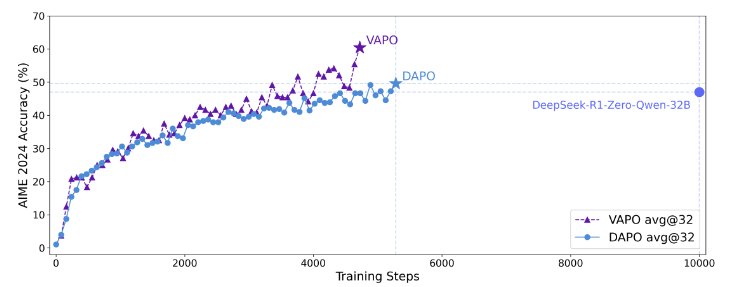
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks VAPO is a new value-based reinforcement learning framework designed to enhance long chain-of-thought reasoning in large language models. Built upon Qwen2.5-32B, it outperforms existing methods in
VAPO: Value-Based RL Framework for Advanced LLM Reasoning
By
–